






























中关村科金外呼机器人端到端语音翻译一瞥

 外呼机器人
外呼机器人
1、背景
语音翻译其实就是将一种语言的音频翻译成另一种语言的文本,也可以直接从一种语言的音频翻译到目标语言的音频。目前所谓的端到到语音翻译是指从一种语言的音频翻译到目标语言的文本。
语音是人类最自然的交互方式。翻译有助于打破语言的障碍,促进人与人之间的沟通与交流,推动文化和信息的传播。可以实现在视频网站上看任意语言的视频生成中文字幕,或者跨国会议实时同传,或者出国旅游的翻译机。
2、级联系统和端到端系统
2.1 级联系统(Cascaded Speech Translation)
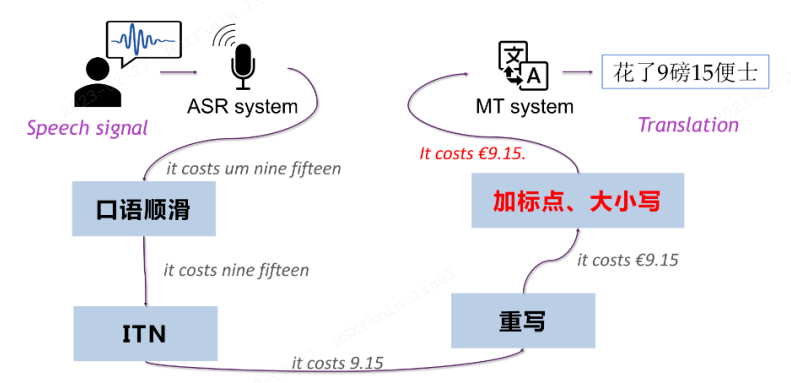
先通过语音识别模型(ASR)来对语音进行转录,然后通过文本翻译模型(MT)对转录文本进行翻译。级联语音翻译仍然是工业界的首选。
优点:
•对语音翻译任务的解耦。 这两部分系统可以分别进行优化,再将其串联起来。并且可以看到系统输出的中间结果,从而对其进行优化,再送给下一个模块的输入。在语音识别模型之后,通常会进行顺滑处理、标点预测等。
•丰富的资源积累。 不管是语音识别亦或是文本翻译,都拥有十分丰富的相关技术与数据积累,在诸多语言上均已经有完备的系统。
•Transformer/Conformer的能力已经经过了充分的验证,统一的架构更是促进了领域的共同发展。
缺点:
•错误传播。 语音识别模型得到的文本如果存在错误,这些错误很可能在翻译过程中被放大,从而使最后翻译结果出现比较大的偏差。
•翻译效率较低。 由于语音识别模型和文本翻译模型只能串行地计算,翻译效率相对较低,尤其在上文描述的实时语音翻译场景。
•语音中的副语言信息丢失。 ASR过程中,语音包含的语气、情感、音调等信息会丢失。同一句话,在不同的语气中表达的意思很可能是不同的。
框图:
2.2 端到端系统(End-to-end Translation)
端到端语音翻译是一个统一的直接将语音翻译成文本的模型。相比级联模型,端到端模型的优势是可以缓解错误传播的问题,还可以简化模型部署的过程。
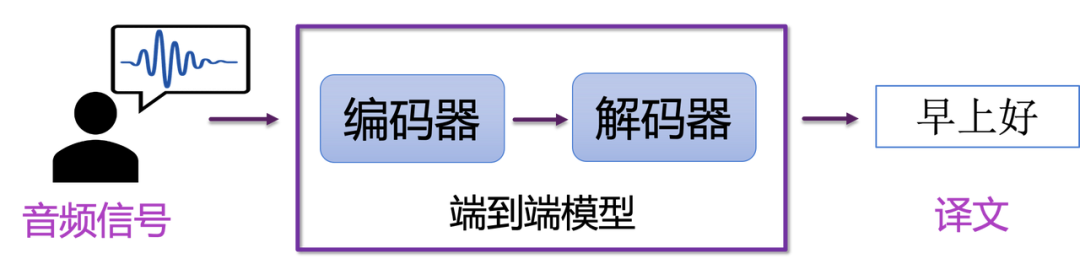
常用的端到端语音翻译模型还是基于 Transformer,
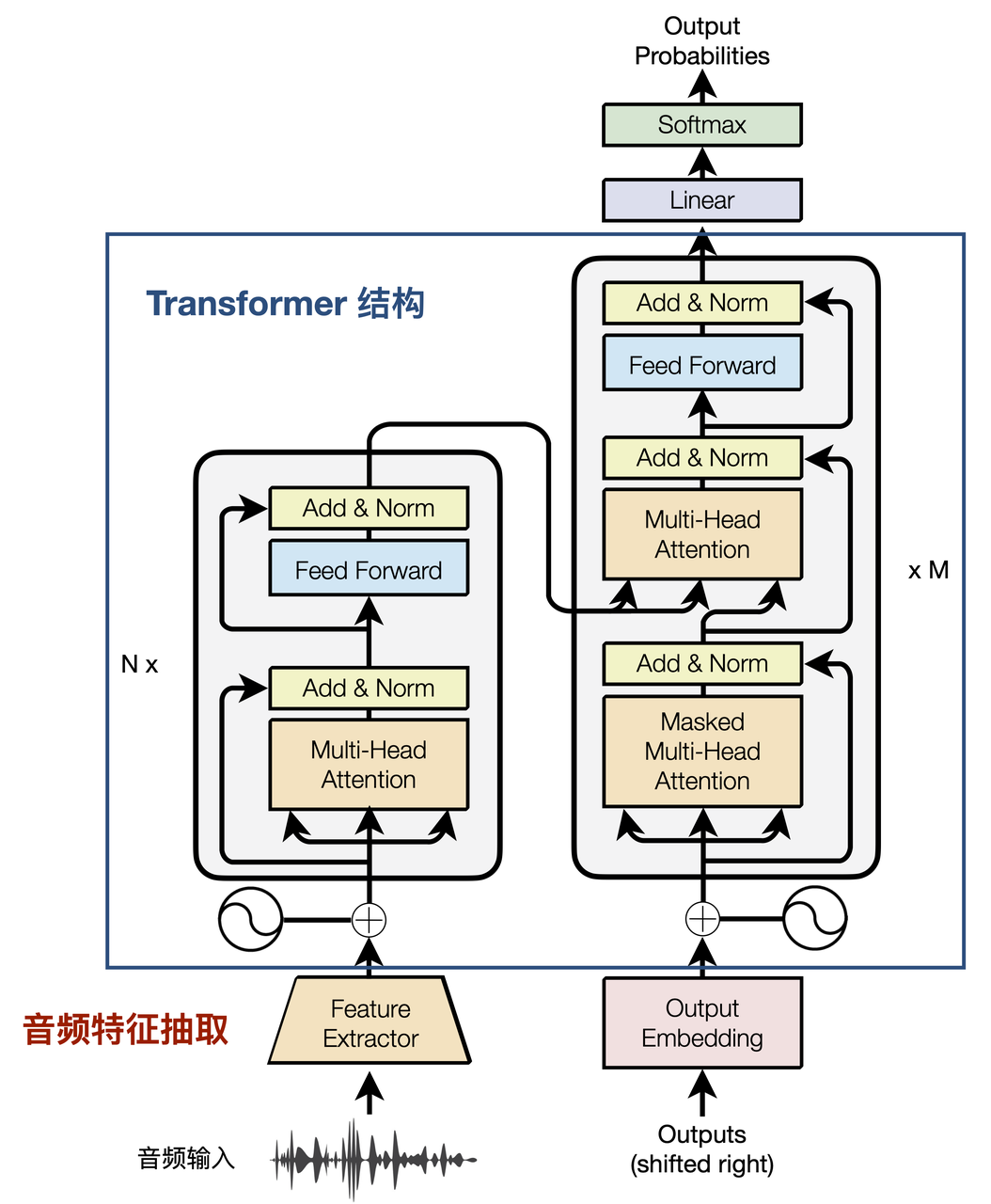
该架构与标准的Transformer架构基本一致,只将编码器的输入层进行了替换,常为FBank特征,然后通过堆叠两个卷积模块对输入特征的长度进行压缩,通常压缩到输入的1/4,从而降低计算过程中的显存消耗。
简单对比级联系统的两个优势,就可以得到端到端系统亟待解决的两个关键难题:
•任务建模复杂。语音翻译模型需要学习从源语言语音到目标语言文本的生成。并且,由于端到端模型并没有中间的输出信息,很难针对翻译过程中出现的问题进行定向的优化。
•数据积累不足。 端到端语音翻译是一个新兴的方向,数据集大都在近几年标注,目前最常用的MUST-C数据集,数据量只有几百个小时音频,对应几十万条数据。数据量的不足是语音翻译发展的最大障碍。
3、端到端建模优化
端到端的建模方法比传统的级联语音翻译更具备潜力,如下推导(X 表示音频输入,S 和 T 分别表示语音识别结果和翻译结果):
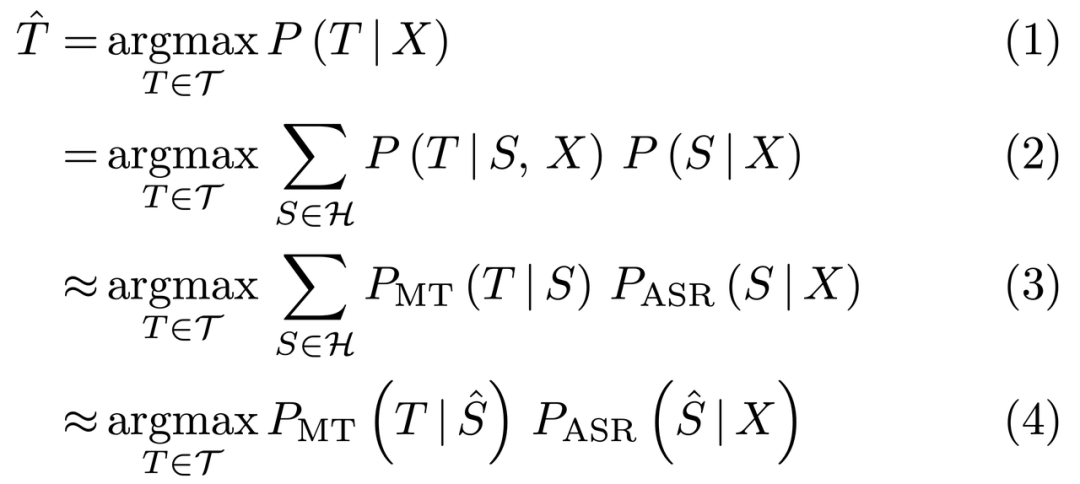
•式(1):即为端到端语音翻译模型,它直接从音频 X 生成译文 T;
•式(2):引入了一个新的变量 S 且为(1)的条件概率展开形式;
•式(3):我们用一个文本翻译翻译模型来近似 P(T | S, X),显然这一步存在信息损失,因为我们忽略了原始的音频输入,导致翻译模型无法真实捕捉到说话人的语气、情感、态度等,进而可能存在歧义;
•式(4):即为级联语音翻译模型,它直接取语音识别模型输出的 Top 1 结果,并传给机器翻译模型。这就回到了前文所述的级联模型的不足之处:一个是语音识别的输出与机器翻译不匹配(如口语化现象、无标点、甚至领域不匹配等),二是错误传播的问题,尤其是在商业语音翻译系统中,往往还包含口语顺滑、标点恢复等模块,潜在累积更多的机器学习模型的预测错误,同时增加了模型复杂度。
3.1 多任务学习
语音翻译中使用多任务学习最经典也是最常用的方法,借鉴了语音识别中模型的设计,在编码器顶层加入连接时序分类(Connectionist Temporal Classification,CTC)[Connectionist Temporal Classification: Labelling Unsegmented Sequence Data with Recurrent Neural Networks]损失项来学习源语言序列的生成[A Comparative Study on Transformer vs RNN in Speech Applications],模型如下图所示。
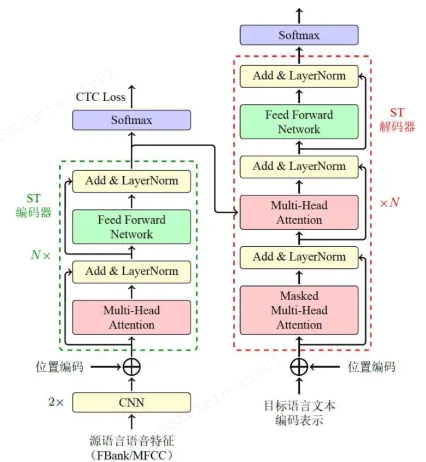
语音翻译任务较为复杂,直接学习源语言音频到目标语言文本的映射非常困难,通过指导编码器学习源语言语义信息可以达到很好的过渡,降低了训练的难度。区别于交叉熵(Cross Entropy, CE)损失要求logit和label之间需要完全对齐,CTC的优点在于可以学习变长序列之间的软对齐关系,即logit和label的长度可以是不等长的,更确切的说是要求logit的长度不小于label长度。
3.2 额外数据辅助
既然语音翻译的一个重要难点在于标注数据积累不足,那么可以将其看作一种低资源任务,自然联想到一些常用方法,即利用额外数据进行辅助,如预训练、数据增强、自监督、自学习等。
•多阶段预训练方法
a.流程分为无标注数据的预训练和有标注数据的预训练。
b.首先利用无标注的音频和文本通过自监督的方式预训练模型,
c.之后在此基础上通过翻译数据和语音识别数据将两个模型训练分别至翻译模型和语音识别模型,
d.最后通过语音翻译数据进行微调,
•无标注数据预训练
○文本预训练: 利用无标注数据进行降噪自编码的方式来减少可能带来的扰动是一种自然而然地办法。这种自编码的方法将大量的无标注源语和目标语文本利用降噪自编码的方式训练出一个适合于下游语音翻译任务的文本模型。
○语音预训练:传统的语音预训练模型是基于经过转换的音频特征来处理,这里使用基于音频预训练的方法。将纯音频作为模型的输入,将一定时长窗口的信息,结合上下文的信息以及量化的方法将其转化为上下文信息的表示,主要使用的是wav2vec 2以及hubert。以wav2vec 2举例,其通过7层卷积网络将50ms窗口内的信息进行了聚合,然后通过码表及对比损失将其量化到有限的空间。
•有标注数据预训练
○翻译预训练:这一阶段我们开始将翻译平行语料引入到模型中,与直接的翻译训练策略不同,我们需要考虑到下游的语音翻译任务,语音识别文本相较于正常的翻译文本,最大的问题在于插入错误,其中大量的重复词和静音问题编码端在翻译模型训练过程中无法识别,我们针对这一问题引入噪声到源语文本中,在源语中引入静音标签,使其解码端根据带有噪音的文本以及原始文本预测同一目标语。这种方式能够使编码端对静音位置的不再敏感,进而使编码端更能关注到实体词抽取出有用的信息。
○语音识别预训练:为了减少预训练模型之间的差异,本阶段设计多重适配器来弥补音频和文本模型之间的表示不一致问题。表示不一致包含了建模粒度的不一致和表示空间的不一致。首先音频编码器的建模粒度小于文本编码器,无法将其直接映射到文本的表示空间,因此同其他语音翻译模型一样,我们引入了卷积网络来对音频特征进行降采样,以确保其能够和文本保持一致的建模粒度。由于无标注音频预训练模型输出的表示为含有上下文的音频特征表示,我们引入了一层conformer结构促使模型实现语音特征到文本的跨模态转换。为了训练对齐编码器,我们使用了CTC 损失将音频编码器输出的特征预测转录文本,同时我们也使用文本模型的词嵌入矩阵,促使跨模态转换的表示对齐到文本预训练模型的表示空间中进而减少预训练模型之间表示空间不一致问题。
4、展望
端到端的方法有发展潜力。但面临数据不足,模型难训练的难题。
端到端语音翻译不仅比级联系统复杂度低,同时效果上更具备潜力。结合数据增强、多任务学习、预训练等方式构建的端到端语音翻译系统,在日常对话翻译上已经具备不错的翻译效果。
参考论文:http://arxiv.org/pdf/2212.01778.pdf




 您的账号体验有效期已结束
您的账号体验有效期已结束