






























中关村科金客服机器人“AIGC——图像生成”产品经理视角调研

 客服机器人
客服机器人
#图像生成 #AIGC #产品
1. 前言
除了大红大紫的GPT系列外,AIGC包含的种类还有图像、3D资产、视频、音频等。其中“图像生成”已经在近几年得到了长足的发展,逐步进入商用化阶段。“图像生成”在一定程度上又是3D资产、视频生成的基础,因此是值得具体分析的。
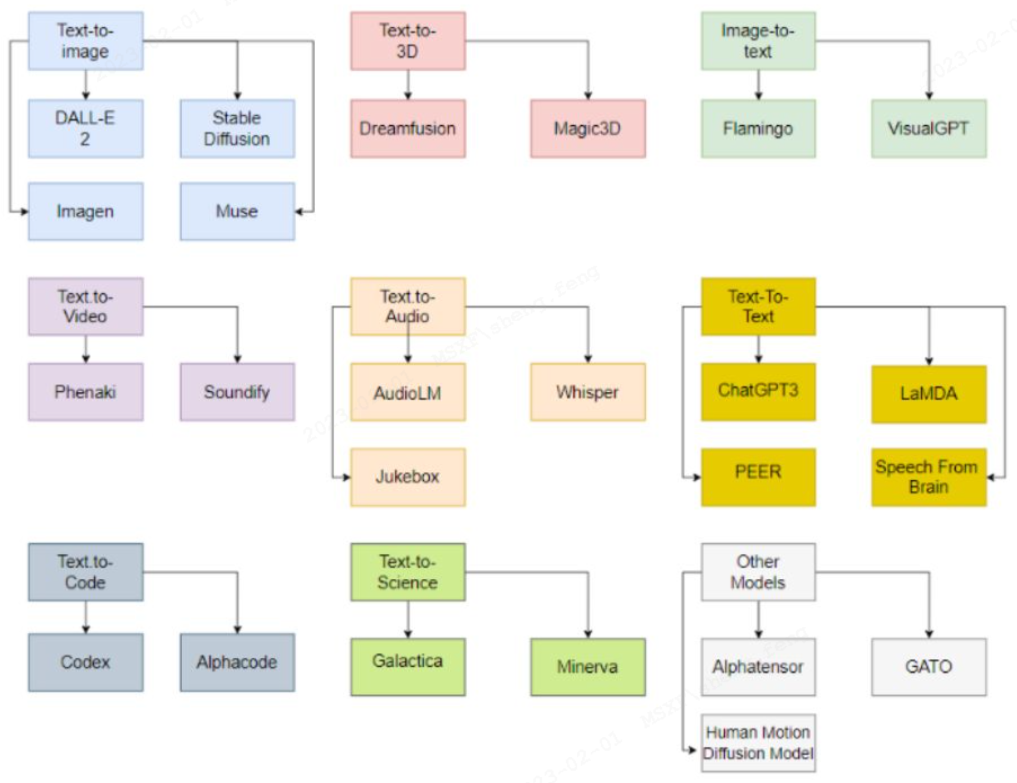
AIGC的主要种类及相关模型

太空歌剧院(美国科罗拉多州博览会艺术比赛上,获得了“ 数字艺术/数字修饰照片”一等奖)
2. 技术
2.1 图像生成技术科普——有哪些技术?技术原理是什么?技术局限性在哪?
2.1.1 图像生成模型概览
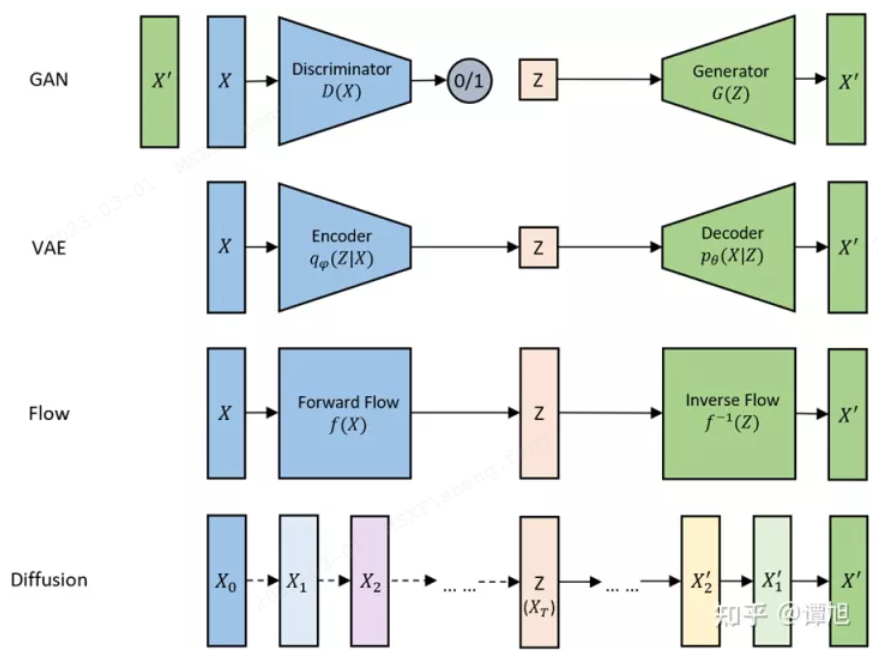
图像生成模型概览
把数据的生成过程,也就是从Z映射到X的过程,比喻为过河。河的左岸是Z,右岸是X,过河就是乘船从左岸码头到达右岸码头。船可以理解为生成模型,码头的位置可以理解为样本点Z或者X在分布空间的位置。不同的生成模型有不同的过河的方法,如下图所示(图中小圆点代表样本点,大圆圈代表样本分布,绿色箭头表示loss)。
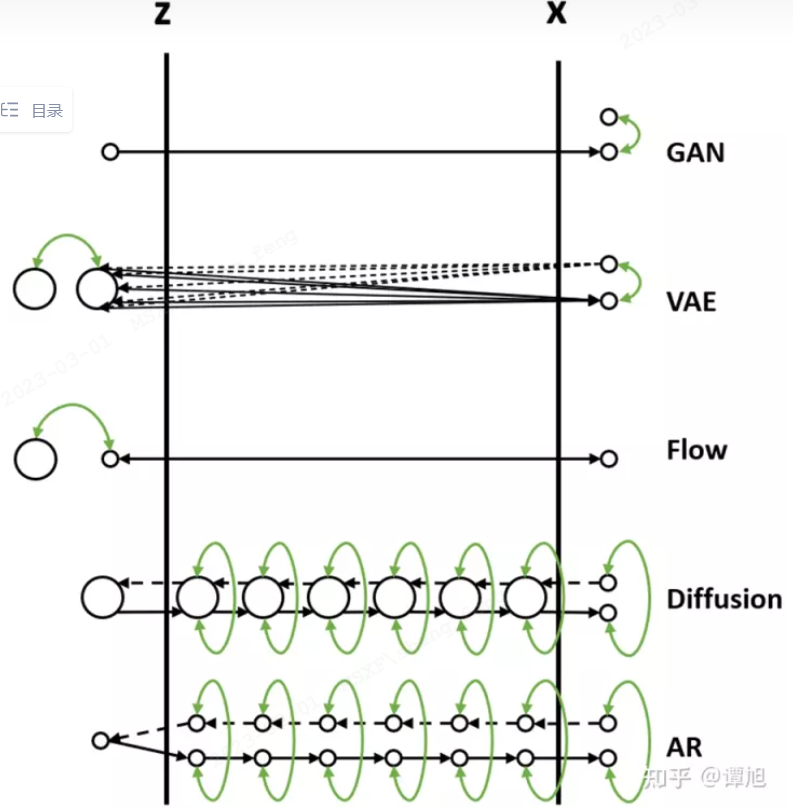
不同生成模型的生成方式
2.1.2 GAN
Diffusion技术出现前,GAN是图像领域最火热的模型选择。GAN(Generative adversarial network,生成对抗网络)的逻辑很简单:训练两个模型,一个叫生成器,专门负责画图,一个叫判别器,专门负责评审生成器画的图到底好不好。如果生成器画得好,判别器就给他奖励,如果画得不好,判别器就给惩罚。于是生成器会努力画得更好,但同时还会努力尝试骗过判别器,让他以为自己画得好。而判别器则反过来,他会不断提高自己对生产器产出的判断能力,只奖励真正好的,强烈打击不好的。
但是GAN存在着若干问题:
首先,这种双核成长不是那么稳定的,有时候甲方压倒乙方,有时候乙方压倒甲方,一旦发生这种情况,整个模型就会崩溃。
其次,他的判别器负责教育生成器好好作画,那么对使用的图片质量要求就很高。否则老师自己都错了,对学生的教育就更加无从说起。
最后,生成器也有问题,他特别怕挨打,所以生成图片是极其保守的,遵循的就是少做少错原则。所以你永远无法期待他画出一个戴着鲜花组成的眼睛的小女孩(只要你的训练集中没有类似图片)。
2.1.3 VAE
与GAN类似,也是使用了隐变量Z生成目标变量X。
1.VAE的核心机制中,变分后验p(Z|X)的学习有很多方法(拟合法/纯数学/PLM法),但方法的表达能力与计算代价是不可兼得的。简单的变分后验表达并不丰富(例如数学公式法),而复杂的变分后验计算过于复杂(例如PLM法)。
2.VAE模型生成出来的图片相对GANs那种直接利用对抗学习的方式会比较模糊,这是由于它是通过直接计算生成图片和原始图片之间的均方误差,所以得到的是一张“平均图像”。
3.当从输入样本的潜在子空间表示进行采样时,高斯白噪声的注入会引起不稳定性。
2.1.4 Normalizing Flow
normalizing flow 的核心机制则要求模型是可逆函数。
2.1.5 Diffusion
GAN的方法简单粗暴,没有任何encoder,直接训练生成器,唯一的难度在于判别器(就是“它们的分布相等吗”的东西)不好做。Diffusion本质就是借鉴了GAN这种训练目标单一的思路和VAE这种不需要判别器的隐变量变分的思路,糅合一下。
1.前向扩散(Forward Diffusion Process),就是下图中的上半截,我们将用于训练的数据,随机添加噪点,一遍遍地添加,直到他变成一张全是噪点的图片。
2.反向扩散(Reverse Diffusion Process),就是下图中的下半截,我们让模型将这张全是噪点的图片,还原成一张清晰的图。
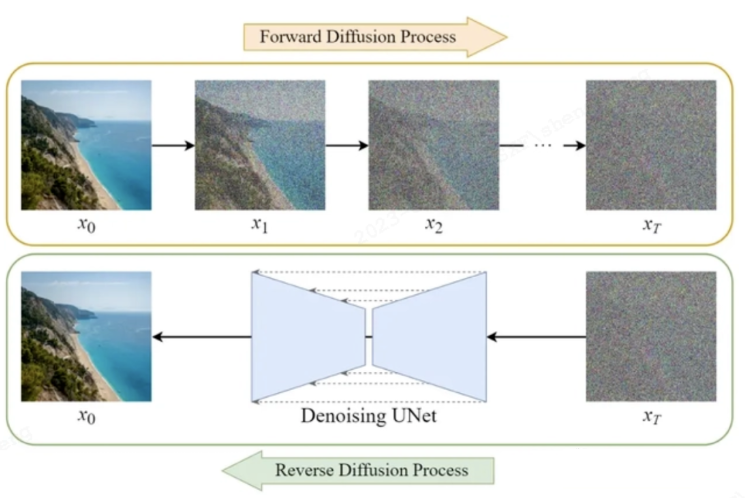
Diffusion模型
AI模型需要在这个加噪点去噪点的过程中,学习到绘画的方法。在这个过程中,AI模型的训练原理如下:
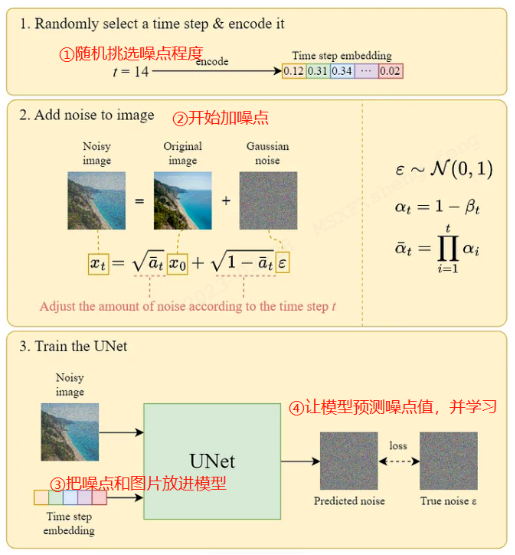
Diffusion模型的训练过程
①第一步,我们随机挑选一个噪点程度,顺便把这个程度数字化(向量化)
②第二步,随机到的结果是噪点程度T=14。我们就给这张照片加上对应程度的噪点,让他糊掉(必须糊成14的程度)。
③第三步,把噪点程度的向量+模糊的图片一起放进神经网络,这个神经网络的学习过程和上面相反,上面是我怎么加噪点让他变成糊图,而他学习我怎么去除噪点才能让他变成美图。
④第四步,学习的过程中会让模型预测出我要去除的噪点(noise)是多少的。与此同时我们是知道真正要去除的噪点值是多少(毕竟是第一步,第二步中这个噪点是我们自己添加的)。所以AI的预测噪点值就可以去和真实噪点值比较,这个差值就是loss了,你可以理解为模型预测的偏差。
⑤循环训练,在刚开始训练的时候,loss是非常大的,但是我们的训练目标就是让loss变小,无限逼近于0。当loss成功变得非常小时,我们就成功了,模型后面每一次去做预测,都能非常准确。
当模型训练完成后,你让他画画的时候,他就只会执行反向扩散过程了,即找出一张全是噪点的画,然后一步步去除噪点,直到生成作品。整个过程就像下面这张图一样。
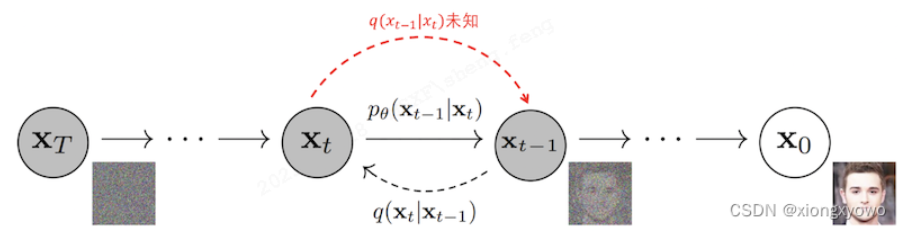
Diffusion模型的预测过程
理论上步长越长,图像就越不糊(去的噪点多了),质量也会越好(预测很多次,更准了)。
2.1.6 CLIP
计算机怎么知道文字和图片之间的关系?在这里再次遇到老朋友OpenAI。他在2021年1月开源了CLIP(Contrastive Language-Image Pre-Training)。这个模型用了40亿的“文本-图像”数据来训练,确保计算机在文字描述和图像之间形成互通。
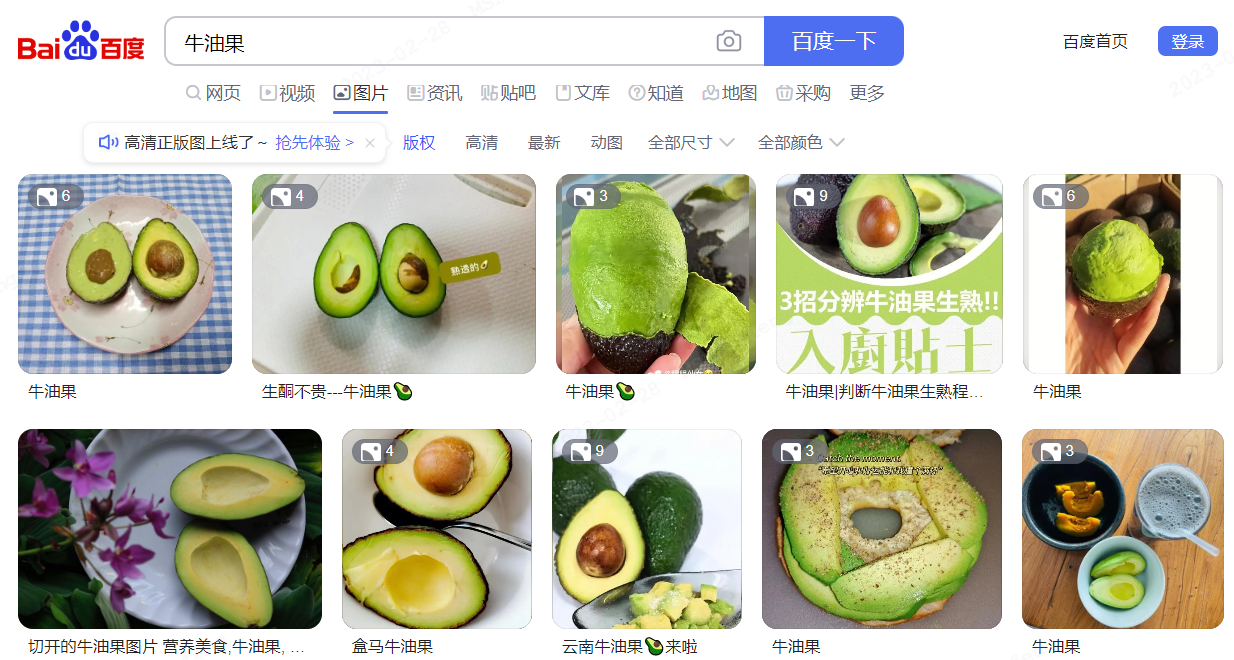
百度搜图“牛油果”结果页面
这些训练数据长啥样,不妨稍微看看牛油果。每张图片下会有这张图片的描述,这就是文本-图像对数据。
OpenAI的这次开源,提供了一条多模态通道,让“以文生图”的效果得到进一步提升(以前不是没有类似的模型,但没有这个效果好)。
现在,当我们说“画一个牛油果椅子”,计算机就会将这句话通过CLIP转换成向量。并且,这个向量同时也是图像的向量,因为CLIP模型已经把图文拉到同一个维度上来理解了。
这就是让计算机根据文字画画的关键模块CLIP,他把文字表达与图片表达拉到一个维度上,使得文字Prompt能够进入Diffusion模型中,去约束图片的生成过程。
另外科普一个小知识点,当AI自己乱画,叫做“无条件图片生成任务”,当AI遵循我们的命令画画,叫“有条件图片生成任务”。文字是其中一种条件,除此以外还有音频(看音乐画图),图像(看图画图),姿势,结构等等。
2.1.7 Stable Diffusion
Diffusion虽然解决了GAN、VAE等其他图像模型的缺点,但他在诞生之初,其实也也存在一个缺点:他的计算速度非常慢,出一次图动不动就是一个小时以上,很难全面推广。这是Diffusion的工作原理造成的,因为他出图的时候,其实就是对着一张充满噪点的图反复去噪,这个过程不是一步到位的,可能要执行成千上万次,这就导致出图速度非常慢。为此学术界做了非常多的努力,但最爆炸的成果来自EleutherAI团队所开源的Stable Diffusion。
更深一层的世界——隐空间(latent space)。这个概念在AI中非常重要,因为他能进一步压缩数据量级,让机器的训练、预测速度提升。比如有一张图片他的像素是512*512=262144个像素点。现在我在不丢失重要信息的前提下,把他拉到64*64的隐空间,那么复杂度仅有64*64=4096,是原来的1.5%!隐空间会通过一些工具,对像素世界中的信息进行选择,只留下高质量、有价值的信息,而其余信息全部丢弃。在这种思想下,因为信息量级降低了,所以计算效率大大提升,但又不会丢失重要信息。
结合步骤解释和下面这张图,感受一下完整版Stable Diffusion的工作原理:
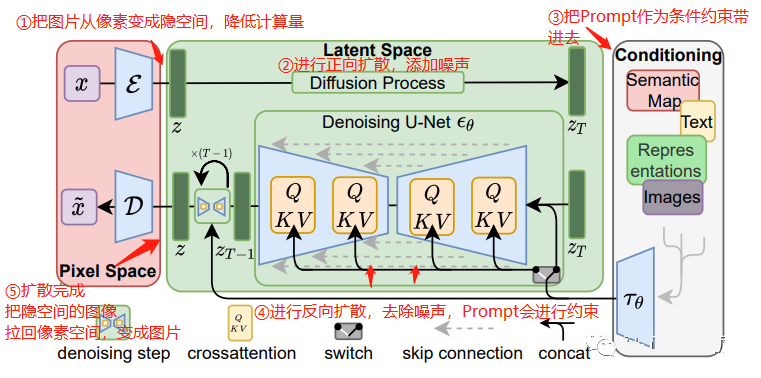
Stable Diffusion的工作原理
①第一步,把像素级别的图片拉到隐空间(减少计算量)
②第二步,进行正向扩散,给图像加噪声(搞一张糊图出来)
③第三步,把Prompt"一个牛油果椅子"转换成向量,一起参与到这个过程中
④第四步,进行反向扩散,让U-net神经网络学习如何正确预测要去除的噪点,这一步会持续反复,直到U-net训练成功
⑤第五步,预测结束后,把图片从隐空间拉回像素空间,成为人类所能理解的图片
整个过程一环扣一环,所以我们可以发现,虽然核心是Diffusion技术,但CLIP、隐空间的应用也都非常重要,所有加起来才推动了AI绘画的爆火出圈。
2.2 图像生成未来技术的发展趋势
在理解基本原理的前提下,大概了解一下技术的变化趋势,避免将思维局限在当前的AI绘画形态上,影响对行业的商业判断。
2.2.1 可控生成
这是目前学术界发力最多的方向。
有体验过AI绘画的同学应该能理解这种烦恼:这张图还不错,但是偏偏某个细节差了点,我又没能力弄下来重新画,只能不停刷新,期望撞大运遇到完美的。
我们可以只替换出错的部分吗?当然没问题!例如下面这张图,我对猫咪骑的单车不满意,我想换成小车,行不行呢?可以的,Prompt的过程中锁定原图,替换一下这个单词就行——这就是语义替换。

小猫骑车语义替换示例
让计算机根据文字生成图片,很关键的一个模块是CLIP来实现这种文本-图像的跨模态转化。并且文字Prompt还会持续约束着Diffusion的去噪过程。而这种可控生成其实就是在这里进行微操,从而实现类似的效果。
要特别关注下图中的右侧的Conditioning模块,他就是我们给Diffusion输入的条件,这里的条件可以是文字,图片、音频、空间结构等等,只是我们目前比较熟悉的应用是文字而已。
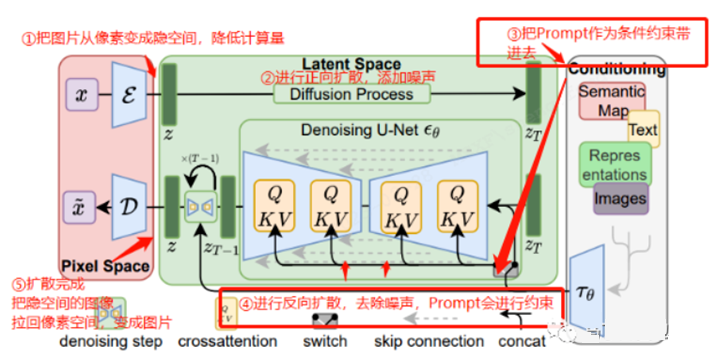
注意右侧的Conditioning模块
除此以外,你甚至可以文字+图两种条件一起上:
1.文字+参考图,按照线框(Hough Line)布局生成图片(通过ControlNet)
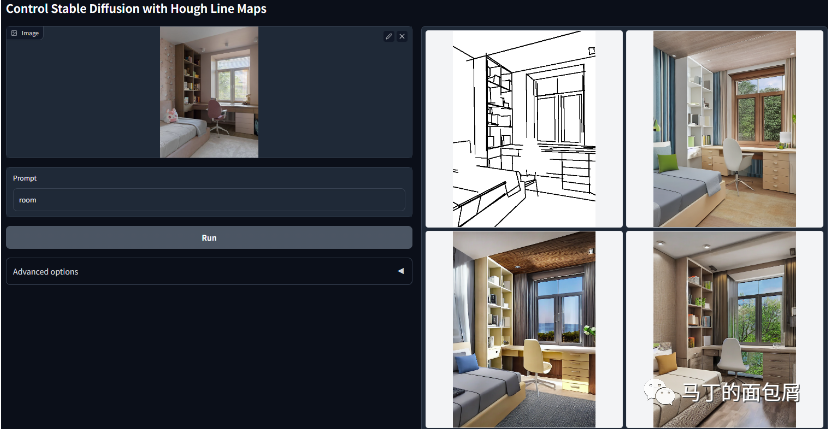
按照线框布局生成图片
2.文字+参考图,限定边界(HED)生成(通过ControlNet)
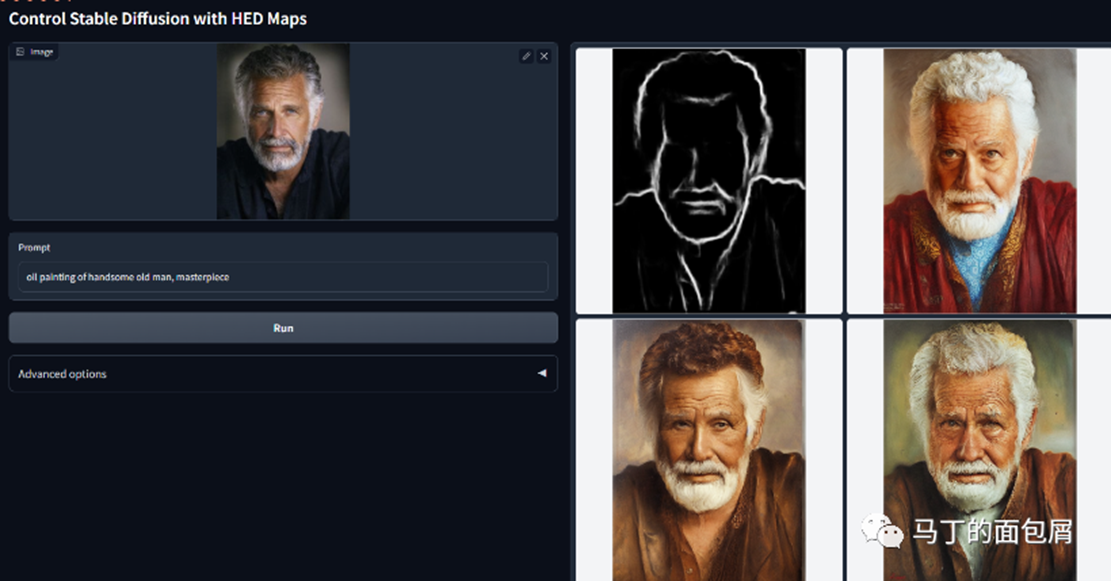
按照限定边界生成图片
3.文字+参考图,模仿人物姿势(Pose)生成(通过ControlNet)
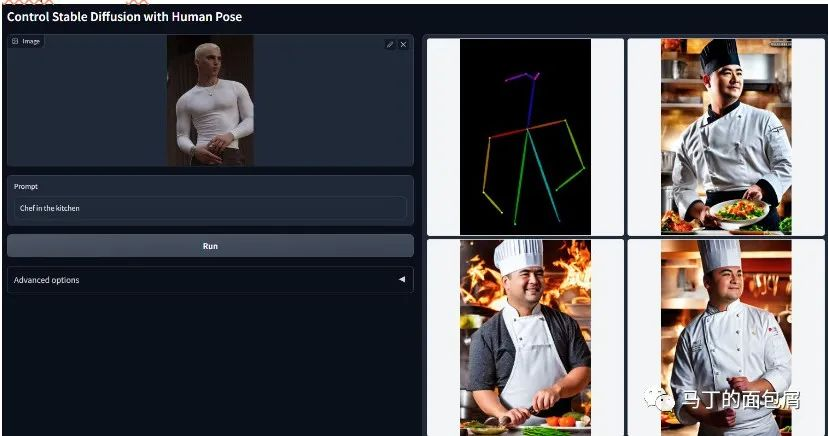
按照人物姿势生成图片
2.2.2 加速采样(降低成本)
不管是Diffusion的模型训练过程,还是上线后的预测(出图)过程,反向去除噪点都是一步步去除的。这种逐步去噪是保证效果稳定的原因之一,但也制约Diffusion的性能成本。
而加速采样就是能够解决这个问题的方法之一,他大概做的事情就是——你要去除1000步才有好效果?我给你直接干到50步!
所以,在去年底还有Stock AI(一家AI绘画公司)倒闭的新闻,到今年就没有任何一家AI绘画公司出问题了。像意间、PAI这样的公司,靠“广告收益+订阅”也活下来了(至少不会盈亏失衡)。
2.2.3 更高的图片质量
从去年7月以来AI的产出质量越来越高。
抛开模型升级的原因不提,很大一部分提升来自更优质的训练数据。这里面一方面来自用户的作品产出,当AI作品被下载,甚至上传到作品集市,那么相当于制作了一个正样本——这是好图,AI你快拿去学习。
此外,一些二维码验证,也在做这方面的数据积累。例如下图,模模糊糊,很明显是Diffusion去噪过程的中间产物。
图形验证码示例
2.2.4 定向微调
一些公司已经在做专门的定向微调优化了。目前能感受到的可能是AI绘画工具上多出了不同绘画风格可选,例如蒸汽朋克、中国画、水墨、动漫等等。
另外可能有一些正在进行的垂直商用的图集训练。例如给他灌入海量LOGO数据,他在LOGO设计方面就会显著提升,这将有助于AI绘画真正踏入商用领域。
2.2.5 更强的语义理解(文本-图像)
目前体验上另一个卡点是,有时候AI不是画不出来,他是不知道我要什么。我明明说要一只粉红色的老虎,但他可能以为是粉红色背景+老虎。这方面的难题就需要靠语义理解去处理。
比如前面提到的CLIP,用40亿文本-图像数据训练出来的。如果我们用一个更强大的模型去替代它,就能够提升绘画过程中的语义准确性。
又比如干脆用ChatGPT来桥接到AI绘画上,这也是一种加强语义理解的方式。当然这需要ChatGPT一起配合,目前ChatGPT的知识中应该还没有Prompt怎么写更合适的知识。
2.2.6 多模态的发展
Diffusion的应用正在扩展到音频、视频、3D领域,但暂时只是一种趋势,落地商用的demo比较少。
3D建模(点云图)的效果可以看看下面这张图

From 《Diffusion Probabilistic Models for 3D Point Cloud Generation》
不管GPT 大语言模型的威力如何强大,他未来是否真的可以跨越多模态降临到图像、音频等多模态,至少在2023年这个节点,图像领域的最佳技术仍然是Diffusion。毕竟有提前半年启动的数据飞轮和学术界数以百计的paper努力。
2.3 图像生成的商业分析——哪些技术目前可以商用?应用领域?市场规模如何?
商业分析主要从以下几个方面进行:
1.需求明确性,需求越明确越无法忍受AI的自由创作,也越需要人类介入校正
2.市场规模,由“作品价值x需求规模”影响。
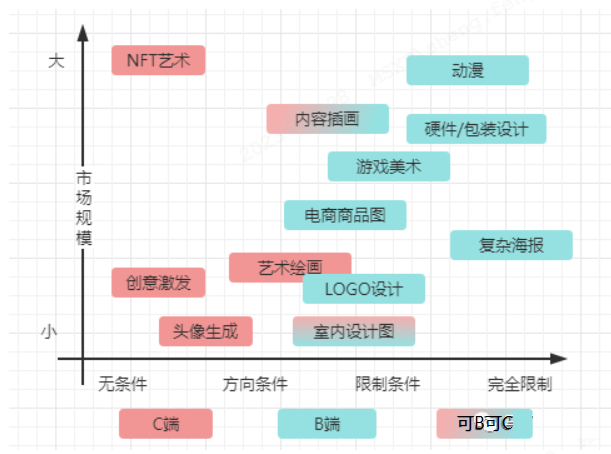
3.分析框架,将“需求明确性、市场规模”组成二维矩阵
4.限制因素,法律版权、敏感审核这两个限制因素
2.3.1 需求明确性
1.需求的明确性受到两方面影响:
1.是否能够想清楚要什么?
多少人/多少场景在创作之前就已经明确知道最后落地作品的样子?
事实上甲方提需求的时候,通常都是朦胧不定的,因为她们心中只有一个概念。并不是所有人都能做到文与可的“胸有成竹”。
2.是否能够说清楚要什么?
一方面因为图像需求的朦胧性,他的表达本身就很有困难。例如“我要一个奢华、有格调、符合品牌调性的海报”,这其实就是朦胧需求带来的表达模糊。
而另一方面是需求方能力限制下的表达模糊。比如梦到了一副作品,那个蓝色是天青蓝还是蝴蝶兰呢?那个画风是印象派还是后现代呢?饱和度是高,还是低呢?
非常难,这也是画师朋友在以前最核心的技能之一。他们在内心通过自己的审美水平建立起了感性-现实之间的通道,并最终通过自己的技艺实现作品的落地。
2.基于上述两个因素组合起来的需求明确性从低到高是这样子的:
1.无条件创作
这就是Diffusion不加入CLIP的样子,即你给我生成一张作品,但我毫无要求,只要是作品就行。在现实中,这种场景的例子非常少,NFT可能算一个(只要漂亮、有艺术感就可以卖钱,不用你命题作文)。
2.方向条件创作
给你一个方向,例如画一张类似莫奈的画,画一只可爱的猫。这个场景就是现在AI绘画目前所完美匹配的场景。他适用于低要求的创作,例如社交货币获取,AI绘画平台作品填充,文章插图等。
3.限制条件创作
商业上的例子会特别常见:帮我画一个LOGO,科技风,里面一定要有潮汕牛肉丸几个字,整体色调蓝色。
这个例子中限定了LOGO,科技风,包含文字,色调等好几个条件,远高于上个层次的要求。
目前技术正在逐渐、部分地满足这个层次的需求。
4.完全条件创作
上个层次中条件完全穷举后即到达这个层次,例如潮汕牛肉丸要在上面,要用衬体字,必须象形写意等等,甲方想要怎么调整就怎么调整。
目前来看,短期内AI不可能是不可能实现完全条件下的创作实现,一定需要靠人类画师借助工具进行二次修改实现。
2.3.2 市场规模
1.单个作品的价值
这里的价值不是使用价值,而是交换价值,你可以用“价格”来替代理解。在AI技术的低成本碾压下,作品的价值肯定会产生断崖式下跌,但需求明确性更高的作品,会具备更高的抗贬值属性。
2.作品的需求规模
即这种类别的商品,有多大的需求空间。例如插画,原本用在故事绘本、日系轻小说等地方。而现在因为技术门槛降低,作品价值下跌,国内的网文,人物立绘,同人作品等场景也会产生需求,推动整体需求规模的爆发。
上述两者综合起来就是市场规模,目前来看基本的方向是价值下跌,但规模扩张,从而迎来整体市场规模的扩展。
2.3.3 分析框架组装
通过这两个维度的理解,我们可以在脑中建立如下图所示的模型,对每个接触到的商业机会进行判断。
“需求明确性、市场规模”组成的二维矩阵
整个图向着右上角蔓延,需求明确性和市场规模在这个框架分析下呈现正比例关系。
但这种关系可能是一种错判,因为其中的市场规模未客观测算,收集的方向也不足够。因此本图仅供参考,无法作为知识输入,可以根据这个框架看看各类投研公司出具的分析报告。
2.3.4 限制因素
Diffusion的限制因素会比ChatGPT简单很多,主要围绕法律版权和敏感审核两方面
1.法律版权
概念上可以分为训练所用图集版权+用户生成图片版权两大类。目前存在大量的争议,没有明确结论。
2.模型的输入:训练图集版权
目前Diffusion原始的训练图集来自Laion(一家非营利性机构)在22年3月开源的Laion-5B(包含58.3亿文本-图像对)。其中最关键的是这个数据集中的一个子集,LAION-Aesthetics。他按照艺术性美感,对图片进行打分,其中8分以上800万张,7分以上1.2亿张。
但可想而知,这么大规模的一个数据集,肯定不全都是具备商用版权的。但目前几乎难以对这方面进行追溯定义,相关的讨论非常混乱。
他面临的本质问题是:对图像的版权定义过时了。AI模型的做法并非像素级复制,甚至非局部复制,而是复制风格、手法、要素等。这种手法有点像媒体界中流行的“洗稿”,几乎无法被追溯版权问题。
所以虽然画家中的抗议声音非常大,在这方面却无法产生太大的影响。

日本画家对mimic的抗议
3.模型的输出:生成作品的版权
目前有一些平台采用附加NFT的做法来保障用户生成作品的版权。但同样的,在法律层面目前没有明确的定义。
如英国,尽管是少数支持AI生成作品版权的国家之一,他对AI生成作品也有着模糊的前置限定——“完成作品创作所需安排的人”。这个所需的人,写几句Prompt算所需的人吗?好像可以算也可以不算。
再例如国内,相关的著作权法中描述,“著作权法所称作品是指文学、艺术和科学领域内具有独创性并能以某种有形形式复制的智力成果”。因此AI肯定不拥有作品的著作权。
再看这条:“我国著作权法第十一条规定,著作权属于作者,受到著作权保护的作者只有两种:“自然人和法人或非法人组织”。那么这个作者是Prompt输入者还是开发AI模型的公司呢?
我能找到唯一相关的判例来自2020年,腾讯的dreamwriter写作的财经新闻被复制转载,腾讯提起诉讼并胜诉,获赔1500元。但这则判例中没有用户+公司这种复杂情况,只有一点点参考意义。
4.敏感审核
审核主要来自输入端(Prompt)和输出端(出图前审核)
Prompt部分比较简单,上个词库+小模型就能解决,比较成熟了。
违规内容检测示例
输出端则会比较承压,毕竟色情和性感,调侃和涉政,其实边界还挺模糊的。常规平台做法一般都是模型+人工双保障。但AI绘画平台目前的收益很难承受得起这种人工审核的成本,所以输出端的控制会松一些。
目前比较主流的方式是通过用户协议进行责任约定,如下图

From 某AI绘画平台 免责声明
3. 用户
3.1 用户群是什么?
典型使用者如:电商从业者,游戏设计师,插画师,原画师,艺术从业者等。
1.创意设计用户(图片精美,具有更强的商业可行性。创意设计用户基数大。)
a.小b端:包括产品设计师(玩具、墙纸),图片设计师(网站、广告、PPT、logo、插图),游戏设计师(游戏场景、角色、道具)以及自媒体创作者
b.企业端:广告公司、影视公司、品牌的广告创意部门等对艺术效果图有大量需求的客户
c.目前Discord中专业设计师占比达30%-40%,包括Nike、adidas、New Balance等公司的设计师。
d.用于设计工作早期,帮助设计师激发灵感,快速测试想法,并迭代图片。设计品牌始终在寻找设计新方法和新工具以提高工作效率,对Midjourney的付费意愿非常强。Midjourney的风格包括很多科幻元素,擅长创造环境图,同时针对人像做了优化,风格较为细腻,非常适合游戏、电影、音乐和出版等创意行业。
 食品广告摄影创意设计
食品广告摄影创意设计
2.工业设计人群
a.建筑设计,建筑师使用Midjourney在项目的最初阶段创建情绪版(mood board:一系列图像、文字或样品拼贴组合物,用来展现设计师对一个项目的想法或感觉)。通过生成的图像激发灵感。建筑师将这些草图翻译成图纸,并建模和进行结构分析,开发出3D模型后,建筑师会再将图像反馈给Midjourney,进一步迭代图纸。近期发布的ControlNet将会进一步深入设计工作流。

钢琴家的房子
3.Web3&NFT从业者
a.Midjourney 目前被广泛应用在 NFT 创作上,因此公司发布规定,如果在“与区块链相关的事物”中使用Midjourney生成图像,需要对每月超过20000美元的收入部分支付20%的版税

NFTs
4.个人爱好者
个人爱好者:自媒体群体,文生图大大降低了艺术创作门槛,使得普通用户也可以成为艺术家和设计师,并通过 AI 创作获取收入。
3.2 这些应用解决了什么业务痛点,带来什么价值?纵向竞品对比,photoshop。
3.2.1 甲方企业:效率高
AIGC的一些图片应用,效率很高,各种画风和想法都可以立即生成出来,而相比之下,公司的原画师不仅画画速度慢,而且很受个人局限,经常想画也画出不来。
近期有公司裁掉了一半的创作人,以原画师为主,这些人原本主要负责设计素材的绘制任务,但在AIGC的冲击下,变得可有可无。一位有10年绘画丰富经验的绘画师,这几天也刚刚被裁员了,因为他所在的原画工作室最近工作量明显减少,他也只是被裁的众多人员之一。
询问了很多不同的公司或工作室,果然,已经有很多设计公司、广告创意公司、策划公司在使用了AIGC后,都已经开展、或者准备开始裁员行动。
3.2.2 C端:降低创作门槛,为C端用户带来“创作”收益
在某社交平台上,已经有多位用户分享了自己完全依靠AI生成的故事绘本:文字由ChatGPT代劳,图画则由Midjourney生成。甚至可以中英双语搭配,直接阅读很难察觉其并非出自人类之手。
据路透社报道,至二月中旬,亚马逊Kindle商店里有超过200本将ChatGPT列为作者的电子书,这个数字每天都在上升。
用ChatGPT创作,再经由自助出版开售,这样做省时省力,而且在TikTok和Reddit等平台上有各种教程,教你如何在几小时内完成一本书,不管是成功学的致富、还是如何节食、编码的技巧、如何制作食谱等等。
不只是实用作品,还有文创作品。在亚马逊官网搜索可以发现,ChatGPT作为作者的书籍,内容主要以虚构类为主,其中儿童故事书占多数,此外还有科幻、浪漫等类型。此类书籍大多通过亚马逊自助出版渠道,也可以通过Kindle Unlimited免费阅读。
《银河皮条客:第一卷》,在亚马逊上该电子书售价1美元,作者显示为弗兰克·怀特(Frank White)。但实际上,这部长达119页的中篇小说,是怀特利用ChatGPT创作的,耗时不到一天。
怀特还在YouTube的一个视频中分享了用ChatGPT创作这部小说的过程,并且告诉大家,只要投入必要的钱和时间,任何人都可以一年生产300部这样的小说。

弗兰克·怀特讲述小说的创作过程
还有一个名叫布莱特·席克勒(Brett Schickler)的销售员,已经在ChatGPT的帮助下实现了自己的作家梦。他在几个小时内就创作出了一本30页的儿童故事书,名为《聪明的小松鼠:储蓄与投资的故事》,通过亚马逊自助出版出售,电子书定价2.99美元,印刷版售价9.99美元。

《聪明的小松鼠:储蓄与投资的故事》亚马逊商城页面
席克勒目前已净赚近100美元。他告诉路透社,这将激励他使用ChatGPT继续写书。
3.2.3 乙方企业(商业文创领域):能出产更多选择,让甲方挑选
用ChatGPT进行创作规划和故事脚本初稿,具体文字也由ChatGPT代劳,图画则由Midjourney生成,甚至可以中英双语搭配,这样甲方想要多少选择就能给多少,又省时省力,还能让甲方高兴。
Chat GPT结合Midjourney进行文创作品产出
所以,在人类的懒惰天性下,在甲方的支持下,在商业贪婪的鼓励下,AIGC替代脑力劳动者的发展一定会继续下去,愈演愈烈。
3.2.4 不同行业对生成图片的不同要求给垂类赛道创业企业提供了机会
1.专注于Logo与网站设计的looka
2.专注于二次元形象生成的NovelAI
3.专注于游戏资产生成的Scenario
4.专注于头像生成的Lensa




 您的账号体验有效期已结束
您的账号体验有效期已结束