






























中关村科金ai外呼机器人声学模型优化器-如何优化FastSpeech合成的梅尔谱

 ai外呼机器人
ai外呼机器人
#TTS, #DDPM, #残差建模
论文简介
论文标题: ResGrad: Residual Denoising Diffusion Probabilistic Models for Text to Speech
论文地址:http://arxiv.org/pdf/2212.14518.pdf
研究单位:帝国理工学院, 微软
前言
降噪扩散模型DDPM成为 AI算法领域新宠,特别是在图像,视频生成领域。在语音合成领域,近两年也有一些降噪扩散的TTS研究,研究结果表明,可以合成接近真人的合成效果。然而由于需要足够量的推理steps,导致其耗时巨大,不适合于生产环境应用。
近年有一些研究,试图通过各种办法,简化推理时需要扩散的 步骤数,来降低推理耗时,实践证明,这些方法都会造成合成结果的音质损失。
本论文认为:既有扩散TTS的问题在于,它们想用DDPM,来学习从文本到语音梅尔特征空间的建模,这个建模空间足够庞大,以至于难以用少量的推理步数,就达成高音质的效果。本论文另辟蹊径,将梅尔谱预测值,跟真值的残差数据空间(Residual Data)作为扩散模型的建模空间,建立了一个轻量级的降噪扩散模型。该模型可以作为一个即插即用的插件模型(Plug-and-Play),将它放在FastSpeech2之后,就可以提升音质,但是相应的可能会增加耗时。不需要重新训练FastSpeech2。
技术过程
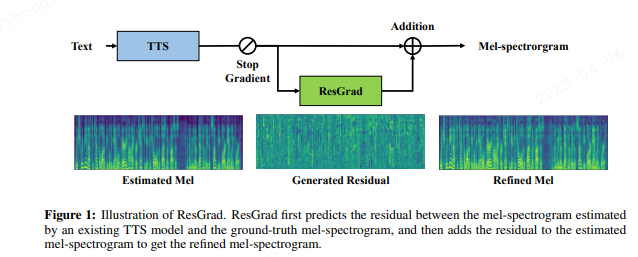
论文以 FastSpeech合成的梅尔谱,跟真实音频梅尔谱中间的残差作为建模对象,来对FS生成的梅尔谱进行音质修正操作,得到的残差值,加上FastSpeech的梅尔谱,得到优质的Refined Mel。
ResGrad is trained to predict the residual between the mel-spectrogram estimated by an existing TTS model and the ground-truth mel-spectrogram, and then adds the residual to the estimated mel-spectrogram to get the refined mel-spectrogram.
目标残差表示为:

mel GT为真值梅尔谱,fφ(y) 中y表示输入文本,f表示 FastSpeech预训练模型。
训练
根据降噪扩散模型一般原理:
训练时,假设残差值分布在[1,T] 这T个离散时间位置上,那么对干净的残差值 x,在每个时间步骤上,用不同的噪声扩张因子β
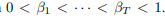
扩张高斯噪音【正态分布】
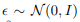
扩张后的噪音加载干净的残差值对应的时间步骤上,将原来的干净残差逐渐扩散成一个类似高斯噪音:
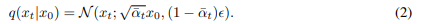
α对应1-β; α平 代表对应步骤上的噪音水平。
本文借鉴了 Grad-TTS的建模方法,函数sθ 表示噪音数据对数密度的梯度函数。建模目标是尽可能拟合真实的扩散密度对数梯度变化情况。
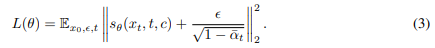
推理
推理时,以预训练声学模型(FastSpeech)输出的梅尔谱为条件, 从高斯噪声数据作为输入中,经过有限步骤的推理计算,得到预估的残差值 x^。 将两者相加得到目标梅尔谱。

实验结果
论文以FastSpeech2为基模型,预训练一个声学模型; HiFiGAN作为声码器。
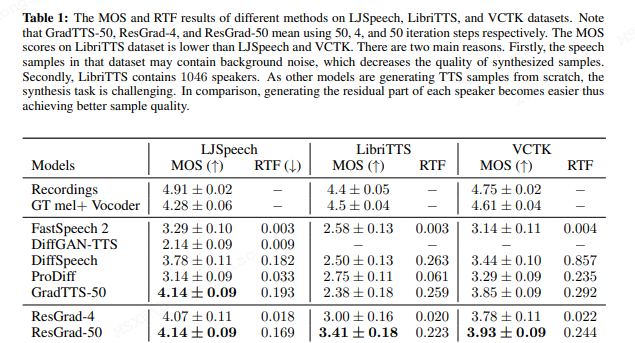
实验在几个知名的开源英文TTS数据集上分别执行,实验表明,ResGrad 扩散到50步时,比GradTTS这种原生的降噪扩散TTS声学模型,音质效果更好,而RTF也小。 而ResGrad扩散到第4步时,音质显著好于原始的FastSpeech2,当然RTF也降低了六倍速左右。
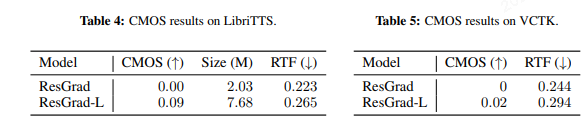
如果使用大扩散模型,还可以进一步提升音质,而RTF损失较小:
案例分析
本论文通过案例分析,发现FastSpeech2生成的梅尔谱,容易出现过平滑【over-smoothing】现象,而过度平滑的谱容易丢失中间的细节。而本论文的ResGrad补全了这些细节,因而得到更好的听觉自然度和语音表现力。通过4个步骤的扩散推理,已经能合成足够好的梅尔残差,来显著提高Fs2合成的梅尔谱的质量。
论文小结
本论文为了解决扩散模型在TTS领域,推理耗时太大的问题,将研究目标指向了建模既有声学模型的梅尔谱跟真实梅尔谱之间的残差值上,降低了模型复杂度,得到了一个很好的FS2合成后处理模型。这个模型作为一个可插拔组件,可以选择用,也可以选择不用。用的时候会牺牲大概六倍的推理耗时,但是极大提升音频质量。




 您的账号体验有效期已结束
您的账号体验有效期已结束