






























中关村科金呼叫中心,一种利用语音预训练模型的文本语音合成方法

 呼叫中心
呼叫中心
论文信息
Title: ParrotTTS: Text-to-Speech synthesis by exploiting self-supervised representations
Author Company: TCS Research
Link: http://arxiv.org/abs/2303.01261
KeyWords: self-supervised, TTS, HuBERT, Adaptive
概论
为什么推荐这篇论文?
既有的成熟的TTS模型,如Tacotron, FastSpeech,都是由两个模块组成的:一个声学模型,来根据文本生成梅尔频谱;一个声码器模型,来将梅尔频谱合成waveform的语音数据。
对于这样的模型,当我们的模型需要新增一个说话人时,就需要采购这个说话人的录音,和对应录音的文本标注。带文本标注的录音是十分昂贵的。所以每次音色扩增都带来较大的成本付出。
本论文,利用语音预训练模型的强大表达能力,完成了一个新的TTS技术栈。在这个技术栈上,得到的多说话人TTS模型,如果需要添加新的音色支持时,只需要少量的该说话人录音即可,不再需要文本,韵律,音素,等标注信息。而且所需录音的量,也比上述传统方法少的多,大大降低了音色扩增的成本。
论文概述
根据本文设计,TTS模型的训练,可以分为两个步骤:第一,教会如何说话【即如何发音】,第二,教会如何朗读【即如何生成文本对应的发音】
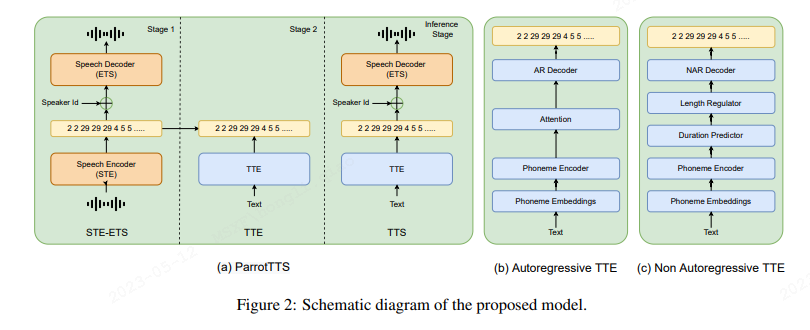
第一步,教会机器说话,本文设计了两个模型:STE和 ETS
1、STE 语音特征抽取器
STE,即 Speech To Speech Embedding。 将原生语音数据,编码为某种抽象特征表示,用它代替我们一般使用的梅尔谱。
编码器必须足够强大,足够泛化,能够编码不同语言,性别,说话人特征的语音数据。所以最好的方法是使用预训练装置。
本论文中,使用了HuBERT 语音自训练模型。但是一般的语音自训练模型,往往是面向ASR设计的,本文用于TTS语音合成,所以作者将HuBERT最后的 classification训练目标,改为了一种 K-Means聚类目标,目的是设计出一种适合TTS的 "码表" 编码。 实验中作者使用了K=100。 我们可以近似认为它表示100种不同的发音音素。【注意跟文本中的音素概念不同,这是聚类出来的,纯声学的一个概念】。
2、E2S 语音合成器
Speech Embedding To Speech。 将所述声学Embedding表示,还原成waveform语音的。 这块模块作者用了HiFiGAN的模型架构,只是模型训练输入从梅尔谱,变成了上述抽取器从Ground Truth训练音频抽取的 Speech Embedding码序列。
作者首先训练了一个单说话人的语音合成器,用于对比实验,标记为SS-E2S。
为了适配多说话人的TTS,所述Embedding表示在输入模型前,还拼接上了 Speaker Embedding。这里可以简单的使用one-hot的Speaker ID就可以了(也可以使用SV说话人识别中得到说话人Embedding复杂向量)。这个多说话人的语音合成器,标记为MS-E2S
可以对语音进行自监督特征表示了,也可以从自监督特征合成语音了,则第一步教会说话就完成了。第二步,是教会如何阅读,也就是如何从文本、音素序列输入,生成为上述Speech Embedding编码。为此,作者设计了一个TTE模块。
3、TTE 文本转换器
TTE 即 Text To Speech Embedding,有点类似之前技术栈里的声学模型,不过它不是从文本生成梅尔谱,而是生成上述的Speech Embedding表示。
作者这里尝试了两种方法,一种是自回归的方法。 第二种模拟FastSpeech2的非自回归的方法。模型框架有类似FastSpeech2: 即seq2seq结构,编码器是Feed-Forward Transformer,解码器部分也是。中间通过cross-attention进行对齐学习。自回归方法的解码器部分,依赖历史解码信息,一步一步解码。而自回归的方法则完全参照FastSpeech2并行解码。
因为这里TTE跟FastSpeech2不同,不是预测梅尔谱,而是预测素食Speech Embedding code。 所以最后的损失函数,从MSE损失,修改为适用于分类的交叉熵损失。
自回归方法训练的转换器标记为 AR-TTE, 非自回归方法的转换器标记为NAR-TTE
TTS最后推理时,将文本通过T2E,得到Speech Embedding,然后输入E2S, 合成语音即可。
实验
通过本论文设计。我们发现,STE 模块基于自训练模型,跟语音说话人是无关的。而它得到的编码也跟说话人无关。而TTE目标是学所述编码,所以TTE也是跟说话人无关的,只是将音素序列生成编码就行了。 真正跟说话人有关的,就是E2S 声音生成器部分。而这部分,相当于声码器组件的部分训练,只需要纯净语音,不需要文本标注的。 这就是本论文价值所在:不需要标注的录音数据,成本要低的多。
为了证明这种说话人解耦能力,作者训练TTE文本编码器时,使用了单说话人的LJSpeech数据集的文本和对应Speech Embedding,而训练 E2S声音生成器时,使用了VCTK数据集的多说话人数据,两者说话人没有交集。
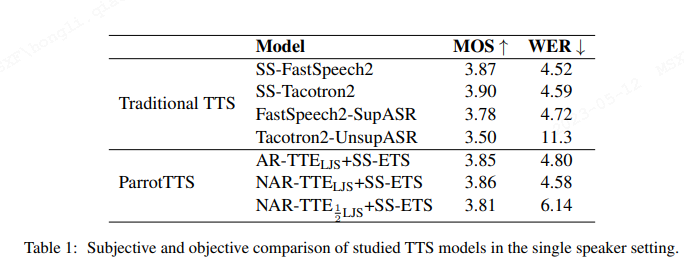

如表1, 在单说话人实验里,文本的ParrotTTS模型,整体得到了跟传统模型相当的合成效果。AR-TTE编码下的音质损失比NAR-TTE下的对应损失更大一些。
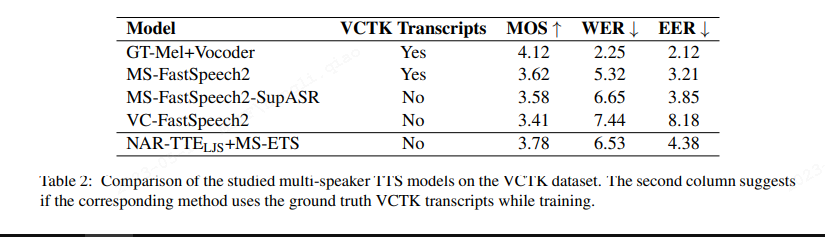
如表2, 多说话人实验里,本论文的文本编码器TTE,跟最后音频生成器ETS训练数据集不交叉的情况下,合成效果优于多说话人的FastSpeech2对应模型。
评价
站在论文作者之外去看,本论文利用了语音自训练表示学习的成果,充分利用了其语音表示特征的强大音色泛化能力,解耦了文本编码学习,和说话人的特征,使得所述语音合成技术栈,可以用较低的数据成本新增说话人音色。这对工程使用有很大意义。另外由于其模型的简化设计,最后的合成速度,比FastSpeech2还要快15%左右。
本文方法的不足,是HuBERT表示学习里,可能也考虑到后边TTE训练的简洁性,对HuBERT的编码输出做了聚类处理。根据论文可以推测,聚类到100个类后,它用了100个聚类中心向量,来代替100个不同的发音编码表示。这种中心向量表示当然是有损的。而由于这个语音表示speech embedding 是整个模型的 灵魂,是声学的特征表示,里边不仅有音高,音调,音色等特征,包括韵律,节奏,音强变化等都在里边。这个有损性就会贯通到各个方面,最终导致模型的合成效果还也只是差强人意的,不够理想化。


-
阿里巴巴国际站 × 中关村科金|多语种语音智能体精准触达全球企业客户
-
东风奕派×中关村科金 | 大模型外呼重塑汽车营销新链路,实现高效线索转化
-
中关村科金x小天才智能客服升级实战案例:全栈AI破局客服痛点,全渠道协同提质增效
-
华润保险经纪×中关村科金:智慧呼叫中心系统,重塑客户连接新体验
-
圣戈班管道×中关村科金:陪练智能体让170年技术积淀在培训中“活”起来


 您的账号体验有效期已结束
您的账号体验有效期已结束