































ASR
独自開発したストリーミング型エンドツーエンド音声言語統合アルゴリズムを活用し、音声を高速かつ高精度でテキストへ変換します。モバイル音声対話、音声コンテンツ分析、ロボットチャットなど多彩なシーンに対応し、金融・自動車・官公庁など各業界の顧客に高精度・低遅延・多言語対応の音声認識サービスを提供します。
コア強み

製品面メリット
- 複数の方言・多言語に対応し、グローバルな業務ニーズに対応
- 騒音など複雑な環境下でも安定した認識を実現、高可用性を確保
- 精度の高い文字起こし結果により、そのままシステムへ実装可能
- HTTP/MRCP/SDKなど各種連携方式に対応

技術面メリット
- 独自開発ASRを大規模言語モデルと密接に連携、意味理解能力を向上
- ストリーミング認識アーキテクチャにより低遅延なリアルタイム文字起こしを実現
- 耐ノイズ性能に優れた堅牢な音声認識モデル
- 膨大なアノテーションデータで学習し、固有名詞向けに最適化済み

サービス面メリット
- 数十業界への導入実績があり、各分野の豊富な導入事例を保有
- 社内膨大な業務環境で検証済み、コアサービスの安定稼働を保証
- 数億規模の日次利用者に対応し、高負荷時でも安定したパフォーマンス
- 業界固有の固有名詞に特化した詳細カスタマイズ・最適化に対応

コスト面メリット
- 複数サービスプランから必要に応じ選択、推論コストを最適化
- 柔軟な課金形態により企業の初期導入費用を削減
- ノイズ除去・VAD機能を標準搭載、別途開発や機器購入不要
- 事後の手作業校正を削減し、校正にかかる人件費を抑制
製品機能
音声前段前処理
 VAD(音声区間検出)によりユーザー発話の開始・終了をスマートに判別します。
VAD(音声区間検出)によりユーザー発話の開始・終了をスマートに判別します。
実環境・疑似騒音の膨大なデータで学習、優れた騒音適応性能を備えています。
テキスト後処理
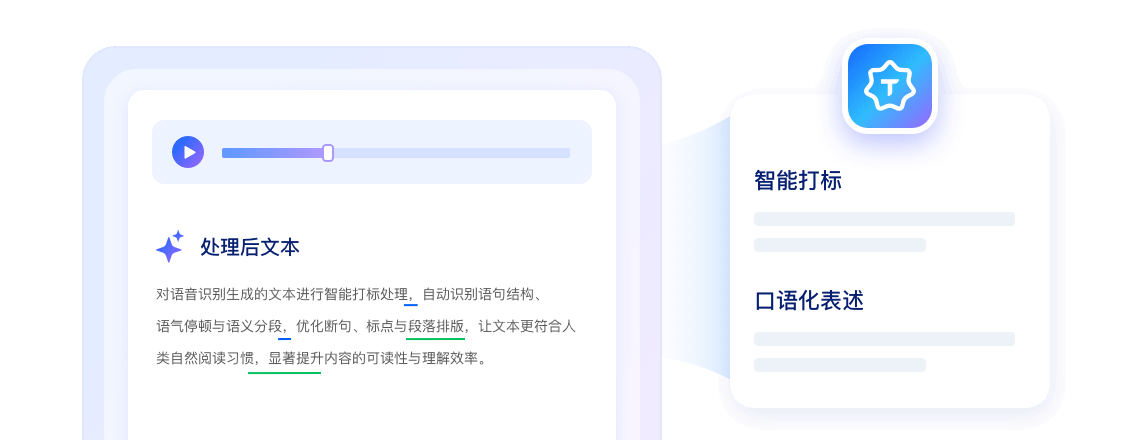
認識したテキストに自動で句読点を付与、可読性を向上させ人間の読み方に適合します。
口語の数値・単位・表記を統一フォーマットへ変換しテキスト正規化を実施します。
品質検査・補助分析
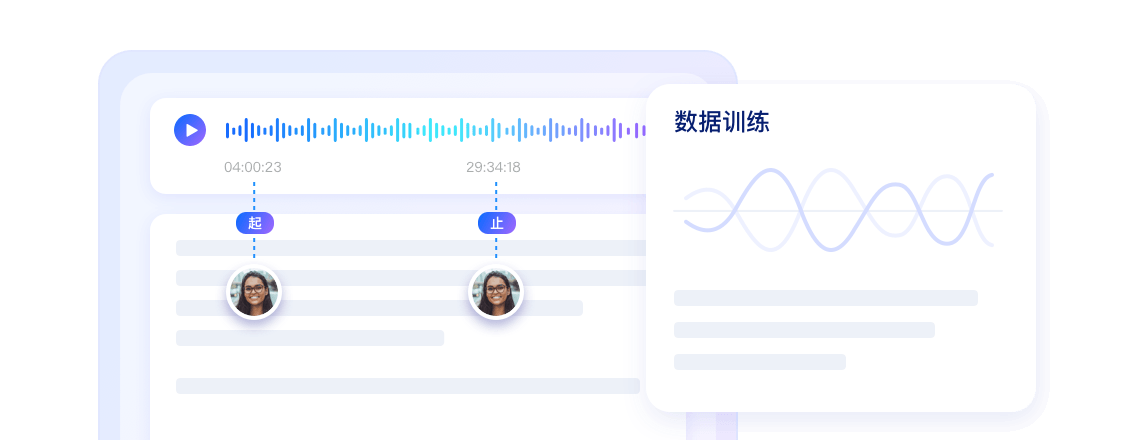
1チャンネル録音の話者分離・種別判定に対応、発話者の切り分けと機械応答を識別します。
リアルタイム音声特徴分析により、通話中の話速・音量変化を常時監視します。

各種音声・動画フォーマット対応
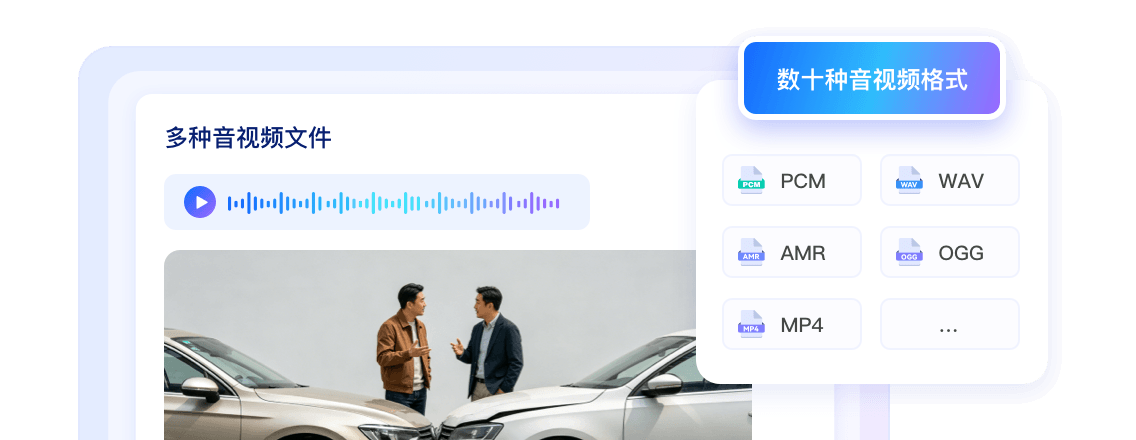
2系統の接続仕様:WebSocketによるリアルタイムストリーミング認識、FFmpeg連携HTTPでオフラインファイルを簡易処理。
PCM、WAV、AMR、OGG、MP4など数十種の音声・動画形式に対応し柔軟に活用可能です。
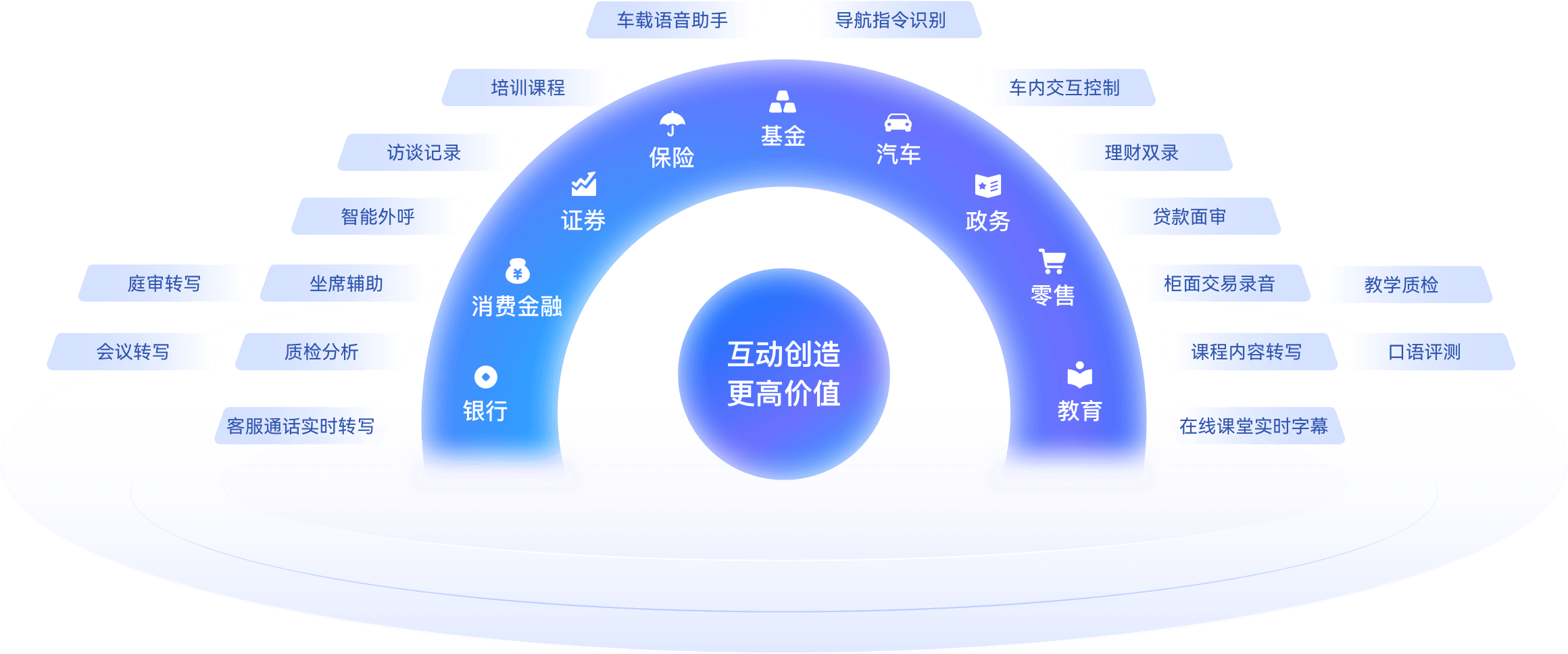
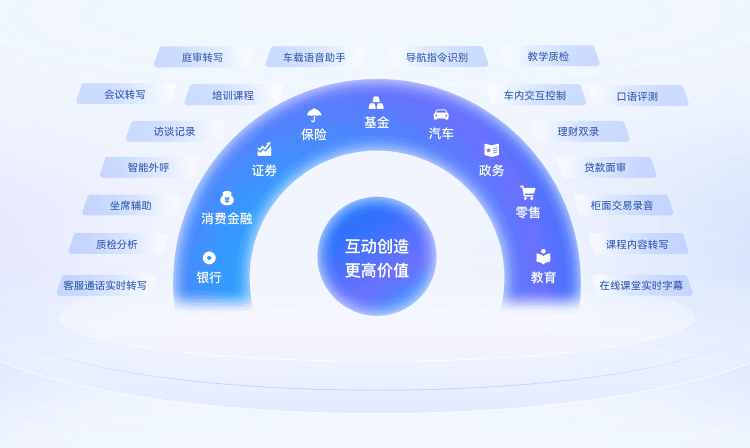
活用シーン

ASR
独自開発のストリーミング型エンドツーエンド音声言語統合アルゴリズムを活用し、音声を高速・高精度でテキストに変換します。モバイル音声対話、音声コンテンツ分析、ロボットチャットなどのシーンに対応し、金融・自動車・官公庁など各業界へ高精度・低レイテンシ・多言語対応の音声認識サービスをご提供します。

コア強み
製品メリット
- 複数の方言・多言語に対応し、グローバルな業務ニーズに対応
- 騒音環境など複雑な現場でも安定認識、高可用性を実現
- 精度の高い文字起こし結果により、そのままシステム導入可能
- HTTP・MRCP・SDKなど各種連携方式に対応
技術メリット
- 独自開発ASRを大規模言語モデルと密連携し、意味理解力を強化
- ストリーミング認識アーキテクチャで低遅延リアルタイム文字起こしを実現
- 耐ノイズ性能に優れた堅牢な音声認識モデル
- 膨大なアノテーションデータで学習、業界固有名詞に最適化済み
サービスメリット
- 数十業界への導入実績、各分野の豊富な活用事例を保有
- 社内膨大な業務で実証済み、コアサービスの安定稼働を保証
- 数億規模の日次ユーザーを支え、高負荷時でも安定稼働
- 業界固有用語向けの詳細カスタマイズ・最適化に対応
コストメリット
- 複数プランから必要に応じ選択、推論コストを最適化
- 柔軟な課金制度で企業の初期導入費用を削減
- ノイズ除去・VAD機能標準搭載、別途開発・機器購入不要
- 事後校正の手作業を削減し、校正にかかる人件費を抑制
製品機能
音声前段前処理
- VAD(音声区間検出)によりユーザー発話の開始・終了を自動判別します。
- 実環境・疑似騒音の膨大なデータで学習し、優れた騒音適応力を備えます。
テキスト後処理
- 認識テキストに自動で句読点を付与、可読性を向上し人間の読み方に適合します。
- 口語の数値・単位を統一表記へ変換しテキスト正規化を実施します。
品質検査・補助分析
- 1チャンネル録音の話者分離・種別判定に対応、発話者と機械応答を識別します。
- リアルタイム音声特徴分析で、通話中の話速・音量変動を常時検知します。
各種音声・動画フォーマット対応
- 2種インターフェース:WebSocketでリアルタイムストリーミング、FFmpeg連携HTTPでオフラインファイル処理。
- PCM、WAV、AMR、OGG、MP4など数十種の音声・動画形式に対応し柔軟に活用可能。
活用シーン








 您的账号体验有效期已结束
您的账号体验有效期已结束
电商出海客户联络解决方案
詳細を見る
全媒体联络中心
詳細を見る
知识图谱平台
詳細を見る
在线客服网站
詳細を見る
自动拨号机器人
詳細を見る
智能云客服
詳細を見る