































TTS
深層学習と大規模モデル技術を基盤に、テキストの感情・抑揚などの特徴をインテリジェントに推測し、人間らしく滑らかで自然な音声合成サービスを提供します。インテリジェントコールセンター、音声読み上げ、ニュース放送、スマート端末など多彩なシーンで活用されています。
コアメリット

製品面メリット
- エンドツーエンド型VITSモデルにより、コールセンター・放送・読み上げ向けなど30種類以上の標準ボイスを実装。大規模モデル駆動TTSによるオリジナル音声クローンに対応します。
- SSMLマークアップ言語によるテキスト編集に対応、各種業務シーンの発音ルール要件を満たします。

技術面メリット
- 高速なエンドツーエンドVITS音声合成と、大モデル活用クローン合成の二方式に対応。
- 8kHz/16kHz二種のサンプリングレート出力に対応、固定電話回線から高品位動画メディアまで幅広い再生環境に適合します。

サービス面メリット
- 自社IVR・アウトバウンドコール・補助アシスタントなど複数業務で実証済み、安定性の高い完成されたソリューションを提供。
- 即時利用可能なクラウドAPIとオンプレミス導入に両対応、データローカライズ法令に準拠。CMA・CNASなど各種権威認証を取得済み。

コスト面メリット
- 従量課金・前払いプランなど柔軟な料金体系を選択可能。
- 独自ボイスクローンに必要な音声素材は5~10秒の超短尺録音でOK、従来の人間録音に比べ大幅なコスト削減を実現。
製品機能一覧
ボイス・音声カスタマイズ
 30種類超の声色・性別・方言ボイスを標準搭載、コールセンター・放送・電子書籍読み上げなど主要業務に対応。
30種類超の声色・性別・方言ボイスを標準搭載、コールセンター・放送・電子書籍読み上げなど主要業務に対応。
大規模モデルTTSにより、サンプル音源をアップロードするだけで独自のクローン音声を作成可能。

詳細な音声制御
再生速度を0~100段階(標準50)で無段階調整、放送テンポを自在に制御。
VITSモデルがSSMLに対応、発音記号・休止・読み方指定タグで細かく発声をコントロール。

リアルタイム音声合成
WebSocketストリーミング合成により生成・再生を並行処理、ミリ秒級の初パケット応答。600文字短文から長文までリアルタイム対応。
大モデルが文章の感情と抑揚を自動解析、感情に合わせた声色を自動選択し自然なリアルタイム会話を実現。

エンタープライズ向けシステム連携
HTTP一括合成、WebSocketストリーミング、MRCPプロトコル、Java/C++ SDKなど複数連携方式を用意。
MRCPによりIVR・アウトバウンドコールなどコールセンターシステムと迅速連携、音声ナビ・自動発信・コンテンツ制作に活用。

活用シーン
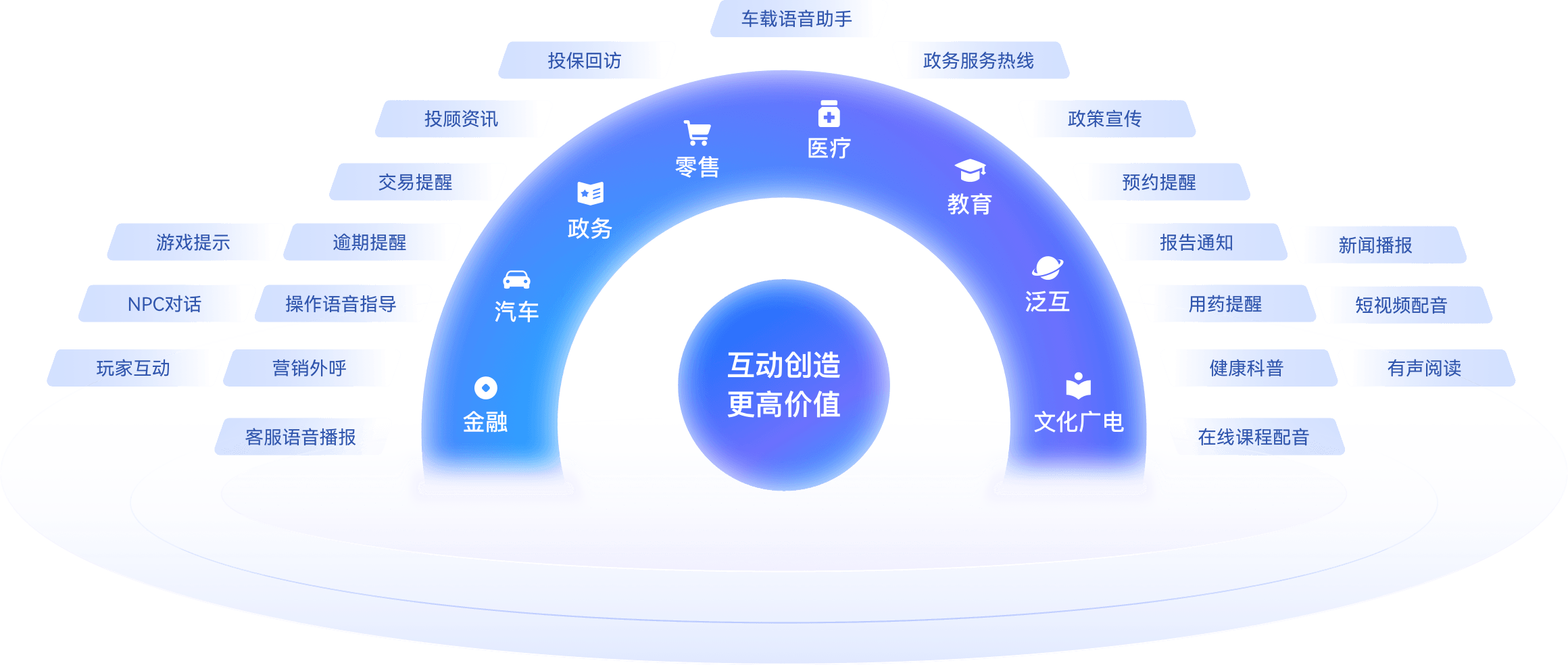

TTS
深層学習と大規模モデル技術を土台に、文章の感情・抑揚などの特徴をAIで予測し、人間らしく滑らかで自然な音声合成サービスを実現。インテリジェントコールセンター、電子書籍読み上げ、ニュース配信、スマート端末など多方面で活用されています。

コアメリット
製品面メリット
- エンドツーエンドVITSモデルにより、コールセンター・放送・読み上げ向けなど30種類以上の標準ボイスを搭載。大規模モデル型TTSによる独自ボイスクローン作成に対応します。
- SSMLマークアップ言語によるテキスト編集に対応、各種業務シチュエーションの発音仕様を実現します。
技術面メリット
- 高速なエンドツーエンドVITS合成と大モデル活用クローン合成の二種類に対応。
- 8kHz/16kHz二つのサンプリングレートで出力可能、固定電話回線から高画質メディアまで全再生環境に適合します。
サービス面メリット
- 自社開発のインテリジェントIVR、アウトバウンドコール、補助アシスタントなどで実証済み、完成度の高い安定ソリューションを提供。
- 即時利用可能なクラウドAPIとオンプレミス導入に両対応しデータローカライズ法令を順守、CMA・CNASなど複数の公的認証を取得済み。
コスト面メリット
- 従量課金・前払いプランなど柔軟な料金プランを選択できます。
- 独自ボイスクローンは5~10秒の短時間音源で作成可能、従来の人間録音と比べ大幅なコスト削減を実現。
製品機能
ボイス・音声カスタマイズ
- 30種類超の声色・性別・方言ボイスを標準実装、コールセンター・放送・読み上げなど主要業務に対応。
- 大規模モデル型TTSにより、音源サンプルを提出するだけで独自クローンボイスを作成可能。
詳細音声制御
- 再生速度を0~100段階(標準50)で無段階調整、放送テンポを自在に制御。
- VITSモデルはSSMLに対応、発音・休止・読み方指定タグで細かく発声をコントロール。
リアルタイム音声合成
- WebSocketストリーミングで生成・再生を並行処理、ミリ秒級初回応答。600文字短文から長文までリアルタイム合成に対応。
- 大モデルが文章の感情・抑揚を自動解析、感情に合わせた声色を自動選択し自然なリアルタイム会話を実現。
エンタープライズ連携
- HTTP単発合成、WebSocketストリーミング、MRCPプロトコル、Java/C++ SDKなど複数連携方式を提供。
- MRCP経由でIVR・アウトバウンドコールなどコールセンターと迅速連携、音声ナビ・自動発信・コンテンツ制作に活用。
活用シーン









 您的账号体验有效期已结束
您的账号体验有效期已结束
智能营销客服
詳細を見る
智能系统客服
詳細を見る
得助全媒体智能客服
詳細を見る
电商出海客服系统解决方案
詳細を見る
ビデオ証跡保存
詳細を見る
视频客服
詳細を見る