































ASR
采用领先的自研流式端到端语音语言一体化建模算法,将语音快速准确识别为文字,支持手机应用语音交互、语音内容分析、机器人对话等多场景,为金融、汽车、政务等领域客户提供高精度、低延迟、多语种兼容的语音识别服务
核心优势

产品优势
- 多方言及语种接入,满足全球化需求
- 复杂环境稳定识别,在噪声下保持高可用性
- 识别结果准确可用,转写文本可直接投入应用
- 支持HTTP/MRCP/SDK等多种方式对接集成

技术优势
- 自研ASR深度融合大模型,增强语义理解
- 流式识别架构,实现低延迟实时转写
- 语音识别模型鲁棒性佳,抗噪声干扰强
- 基于海量标注数据训练,针对专有名词优化

服务优势
- 数十个行业成功落地,拥有多领域成熟案例
- 经过内部海量业务验证,核心场景稳定运行
- 日服务亿级用户,高并发下稳定可靠
- 支持专有名词场景,可深度定制优化适配

成本优势
- 多规格版本按需对接,优化模型推理成本
- 计费模式灵活可选,降低企业初期投入
- 内置降噪VAD等能力,无需额外采购开发
- 减少人工二次处理,节省后期校对人力成本
产品能力
前端预处理
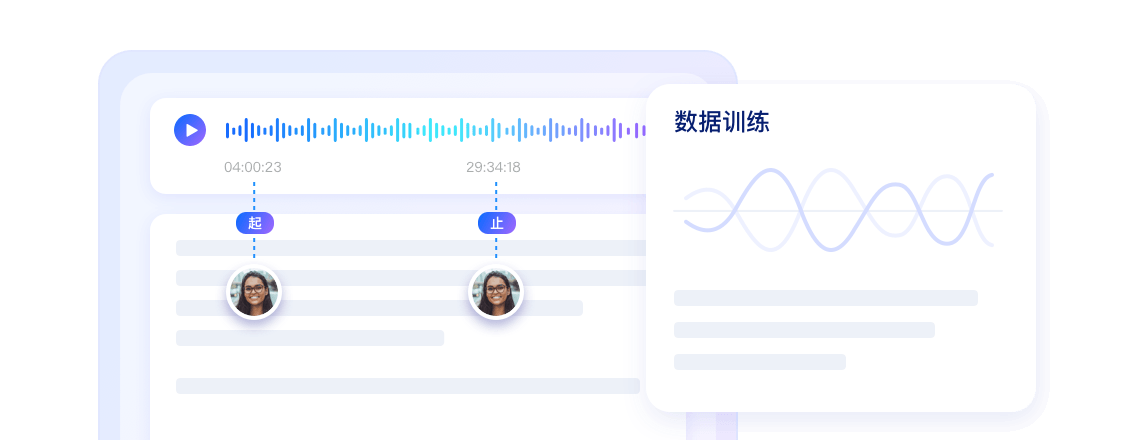
 语音激活检测(VAD)可智能检测用户说话的起止位置
语音激活检测(VAD)可智能检测用户说话的起止位置
通过海量真实与模拟噪声数据训练,具备强大的噪声适应能力
文本后处理
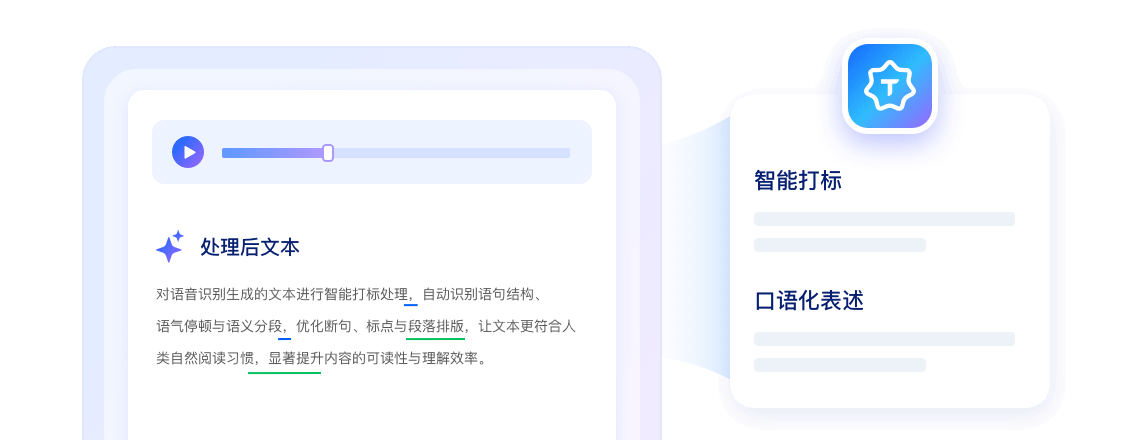
为识别文本智能打标,增强可读性,符合人类阅读习惯
将数字、单位等口语化表述转换为规范格式,文本归一化
质检与辅助分析
支持在单通道录音中进行角色分离与状态识别,有效区分不同说话人并判断非真人接听情况
提供实时语音特征分析,持续检测通话中的语速与音量变化

支持多种音视频编码
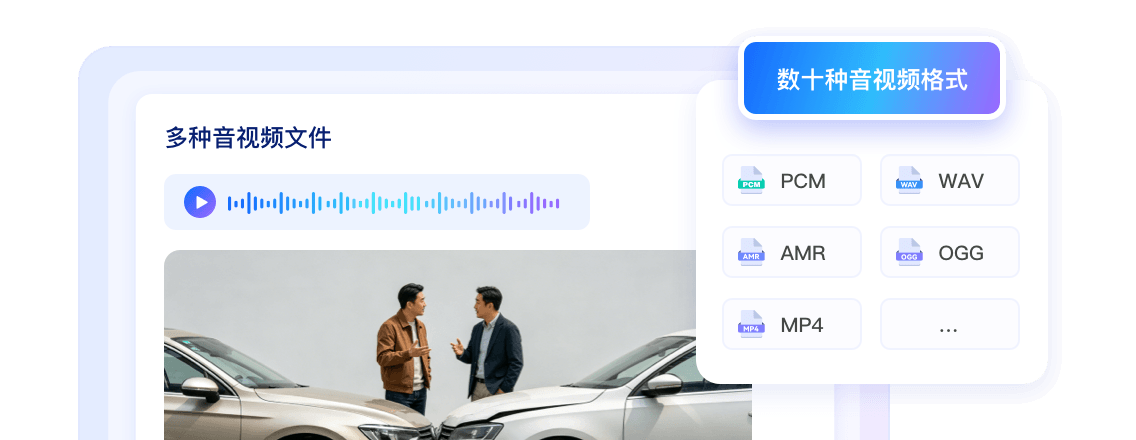
双接口接入,WebSocket支持实时流识别,http接口集成ffmpeg,轻松处理离线文件
兼容PCM、WAV、AMR、OGG、MP4等数十种音视频格式,灵活适配多种音视频文件
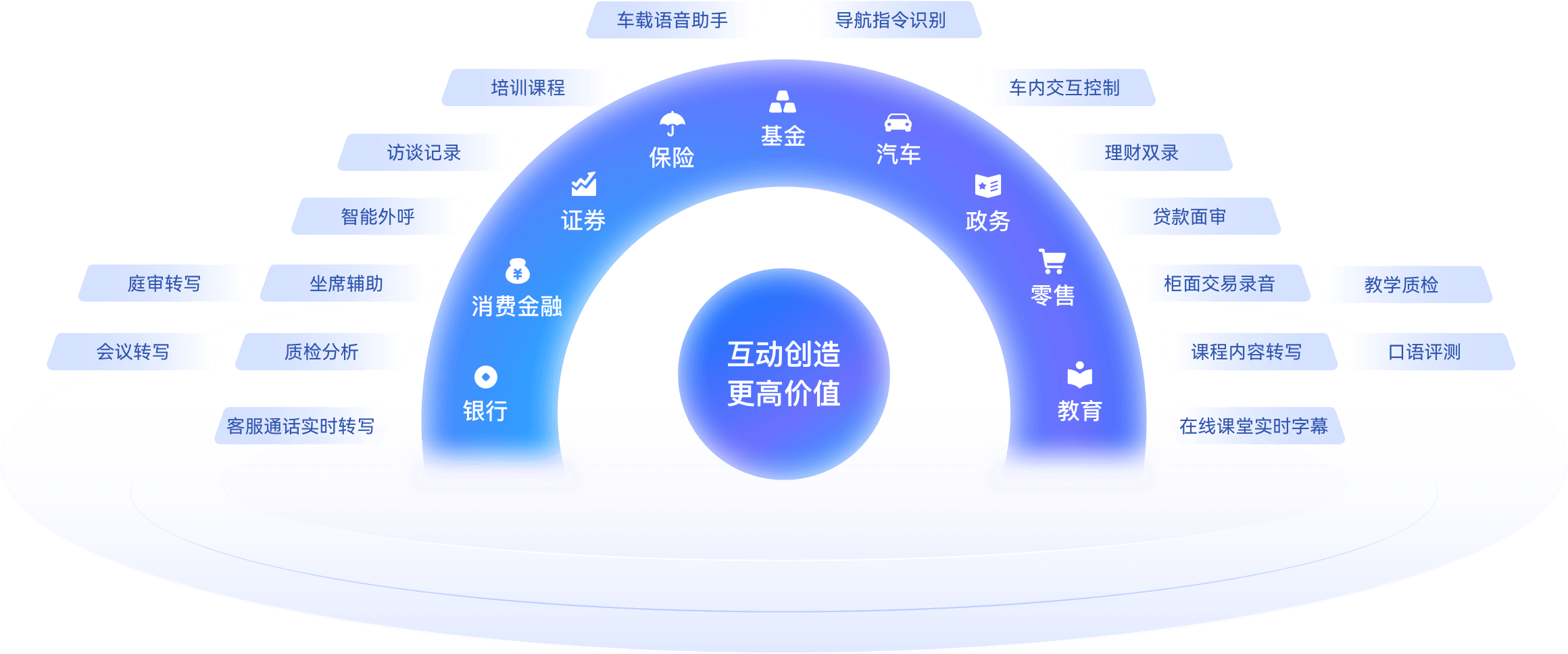
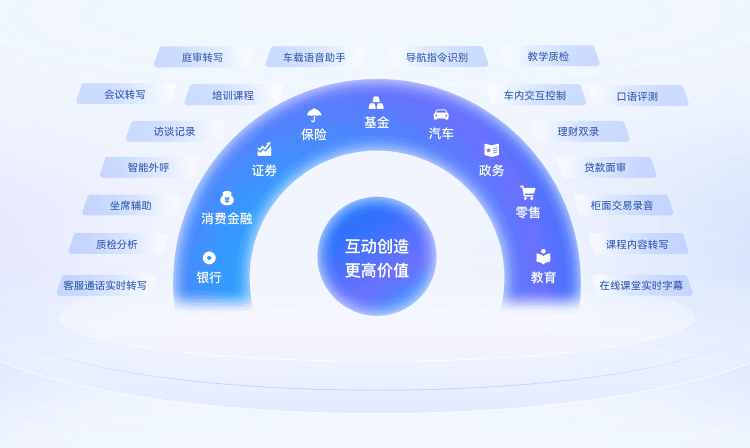
应用场景
相关产品
ABOUT

ASR
采用领先的自研流式端到端语音语言一体化建模算法,将语音快速准确识别为文字,支持手机应用语音交互、语音内容分析、机器人对话等多场景,为金融、汽车、政务等领域客户提供高精度、低延迟、多语种兼容的语音识别服务

核心优势
产品优势
- 多方言及语种接入,满足全球化需求
- 复杂环境稳定识别,在噪声下保持高可用性
- 识别结果准确可用,转写文本可直接投入应用
- 支持HTTP/MRCP/SDK等多种方式对接集成
技术优势
- 自研ASR深度融合大模型,增强语义理解
- 流式识别架构,实现低延迟实时转写
- 语音识别模型鲁棒性佳,抗噪声干扰强
- 基于海量标注数据训练,针对专有名词优化
服务优势
- 数十个行业成功落地,拥有多领域成熟案例
- 经过内部海量业务验证,核心场景稳定运行
- 日服务亿级用户,高并发下稳定可靠
- 支持专有名词场景,可深度定制优化适配
成本优势
- 多规格版本按需对接,优化模型推理成本
- 计费模式灵活可选,降低企业初期投入
- 内置降噪VAD等能力,无需额外采购开发
- 减少人工二次处理,节省后期校对人力成本
产品能力
前端预处理
- 语音激活检测(VAD)可智能检测用户说话的起止位置
- 通过海量真实与模拟噪声数据训练,具备强大的噪声适应能力
文本后处理
- 为识别文本智能打标,增强可读性,符合人类阅读习惯
- 将数字、单位等口语化表述转换为规范格式,文本归一化
质检与辅助分析
- 支持在单通道录音中进行角色分离与状态识别,有效区分不同说话人并判断非真人接听情况
- 提供实时语音特征分析,持续检测通话中的语速与音量变化
支持多语种音视频编码
- 双接口接入,WebSocket支持实时流识别,http接口集成ffmpeg,轻松处理离线文件
- 兼容PCM、WAV、AMR、OGG、MP4等数十种音视频格式,灵活适配多种音视频文件
应用场景








 您的账号体验有效期已结束
您的账号体验有效期已结束
客服坐席
查看详情
外呼电销机器人
查看详情
外呼系统机器人
查看详情
国际化客户联络中心
查看详情
呼叫中心系统
查看详情
电销外呼机器人
查看详情