































TTS
基于深度学习与大模型技术,智能预测文本的情绪、语调等信息,提供高度拟人、流畅自然的语音合成服务,广泛适用于智能客服、有声阅读、新闻播报、智能终端等应用场景
核心优势

产品优势
- Vits端到端模型提供30+种预置音色,覆盖客服、播报、阅读等多场景,以及支持大模型TTS能力的个性化克隆
- 支持SSML标记语言加工文本,满足用户在不同情境下的发音需求

技术优势
- 同时支持端到端VITS的高效合成与大模型克隆合成
- 支持8k/16k双采样率音频输出,全面兼容从PSTN电话信道到高清媒体的播放需求

服务优势
- 已经过智能IVR、外呼、陪练等得助内部业务充分验证,方案成熟可靠
- 支持公有云API即接即用与私有化部署,满足数据不出域合规要求,并已通过CMA、CNAS等多项权威认证

成本优势
- 提供弹性计费方案(按需付费与预付费)
- 定制音色仅需5-10s超短时长即可完成克隆,有效降低传统真人音色复刻的成本
产品能力
音色与语音定制
 内置30+种多风格、多性别、多方言音色,满足客服、播报、阅读等主流业务场景需求
内置30+种多风格、多性别、多方言音色,满足客服、播报、阅读等主流业务场景需求
大模型TTS能力支持用户通过提交音频样本,自主训练生成个性化克隆音色,快速实现声音定制

精细化语音调控
支持0-100级语速参数调节,默认值为50,实现播报节奏的无级精细控制
Vits模型兼容SSML标记语言,可运用phoneme、break、say-as等标签,精确控制发音、停顿及特定读法

实时语音合成
WebSocket流式合成边合成边播报,首包响应毫秒级,支持600字符短文本与超长文本实时合成
大模型智能预测文本情绪语调,自动匹配相应情感表达,支撑高自然度实时对话场景

企业级系统对接
提供HTTP单次合成、WebSocket流式合成、标准MRCP协议及Java/C++SDK多种集成方式
通过MRCP协议与IVR、智能外呼等呼叫中心系统快速对接,适用于语音导航、自动外呼及内容生产场景

应用场景
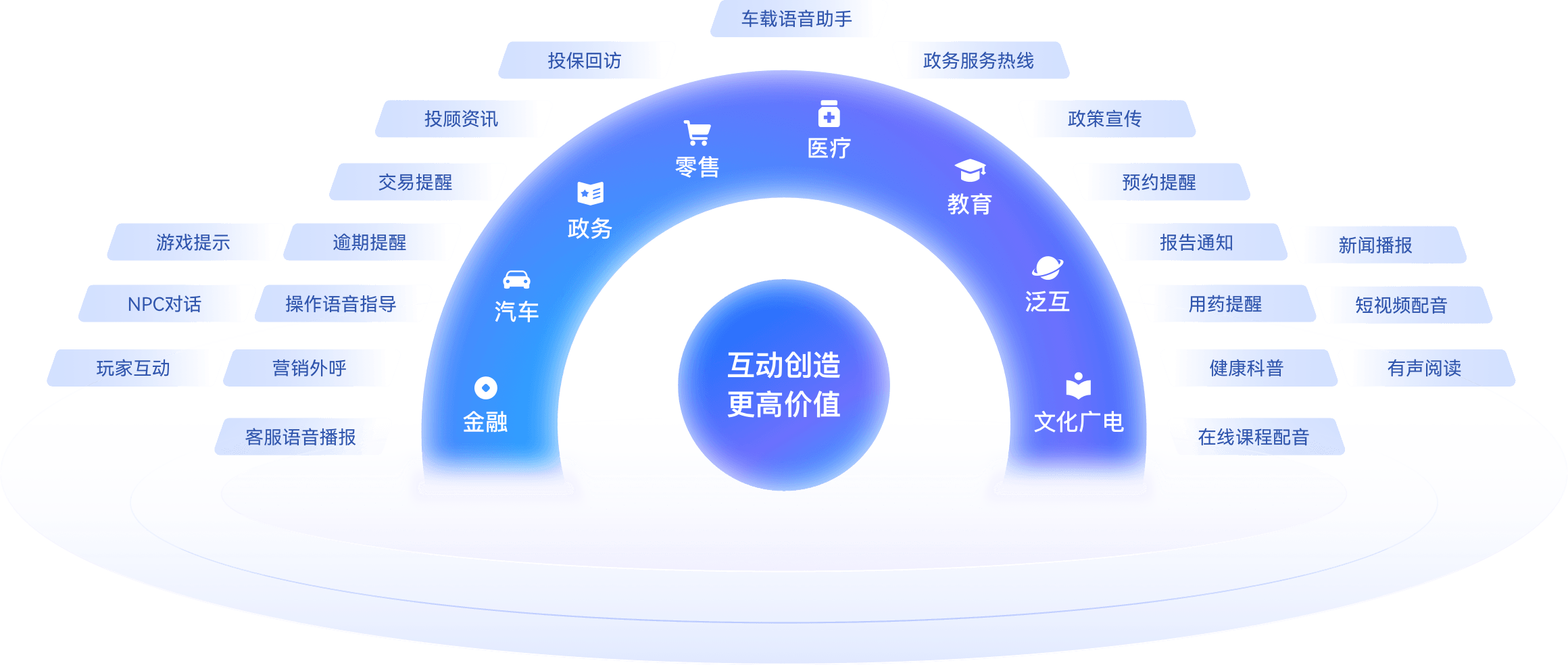
相关产品
ABOUT

TTS
基于深度学习与大模型技术,智能预测文本的情绪、语调等信息,提供高度拟人、流畅自然的语音合成服务,广泛适用于智能客服、有声阅读、新闻播报、智能终端等应用场景

核心优势
产品优势
- Vits端到端模型提供30+种预置音色,覆盖客服、播报、阅读等多场景,以及支持大模型TTS能力的个性化克隆
- 支持SSML标记语言加工文本,满足用户在不同情境下的发音需求
技术优势
- 同时支持端到端VITS的高效合成与大模型克隆合成
- 支持8k/16k双采样率音频输出,全面兼容从PSTN电话信道到高清媒体的播放需求
服务优势
- 已经过智能IVR、外呼、陪练等得助内部业务充分验证,方案成熟可靠
- 支持公有云API即接即用与私有化部署,满足数据不出域合规要求,并已通过CMA、CNAS等多项权威认证
成本优势
- 提供弹性计费方案(按需付费与预付费)
- 定制音色仅需5-10s超短时长即可完成克隆,有效降低传统真人音色复刻的成本
产品能力
音色与语音定制
- 内置30+种多风格、多性别、多方言音色,满足客服、播报、阅读等主流业务场景需求
- 大模型TTS能力支持用户通过提交音频样本,自主训练生成个性化克隆音色,快速实现声音定制
精细化语音调控
- 支持0-100级语速参数调节,默认值为50,实现播报节奏的无级精细控制
- Vits模型兼容SSML标记语言,可运用phoneme、break、say-as等标签,精确控制发音、停顿及特定读法
实时语音合成
- WebSocket流式合成边合成边播报,首包响应毫秒级,支持600字符短文本与超长文本实时合成
- 大模型智能预测文本情绪语调,自动匹配相应情感表达,支撑高自然度实时对话场景
企业级系统对接
- 提供HTTP单次合成、WebSocket流式合成、标准MRCP协议及Java/C++SDK多种集成方式
- 通过MRCP协议与IVR、智能外呼等呼叫中心系统快速对接,适用于语音导航、自动外呼及内容生产场景
应用场景









 您的账号体验有效期已结束
您的账号体验有效期已结束
财富助手
查看详情
Instadesk
查看详情
音视频服务平台
查看详情
智能体平台
查看详情
会话助手
查看详情
智能风控
查看详情