































TTS
Built on deep‑learning and large‑model technologies, it intelligently predicts text emotion, intonation and other features to deliver highly human‑like, smooth and natural speech synthesis services. It is widely applied in intelligent customer service, audio reading, news broadcasting, smart terminals, and other scenarios.
Core Advantages

Product Advantages
- The end‑to‑end VITS model offers 30+ preset voices covering customer service, broadcasting, reading and other scenarios, and supports personalized voice cloning powered by large‑model‑based TTS capabilities.
- Supports SSML markup language for text processing to meet pronunciation requirements under various scenarios.

Technical Advantages
- Supports both efficient end‑to‑end VITS synthesis and large‑model‑driven cloning synthesis.
- Provides dual‑sampling‑rate audio output (8k/16k), fully compatible with playback needs from PSTN telephone channels to high‑definition media.

Service Advantages
- Fully validated by internal Dezhu businesses including intelligent IVR, outbound calls, and practice assistants, it delivers mature and reliable solutions.
- Supports ready‑to‑use public‑cloud APIs and private deployment to meet data‑localization compliance requirements, with multiple authoritative certifications such as CMA and CNAS.

Cost Advantages
- Flexible billing plans including pay‑as‑you‑go and prepaid options.
- Custom voice cloning requires only 5–10 seconds of audio, greatly reducing the costs of traditional voice replication.
Product Capabilities
Voice & Speech Customization
 Built‑in 30+ multi‑style, multi‑gender and multi‑dialect voices to meet mainstream business scenarios such as customer service, broadcasting and reading.
Built‑in 30+ multi‑style, multi‑gender and multi‑dialect voices to meet mainstream business scenarios such as customer service, broadcasting and reading.
Large‑model‑powered TTS enables users to independently train personalized cloned voices by submitting audio samples for rapid voice customization.

Fine‑grained Speech Control
Supports speech‑speed adjustment from level 0 to 100 (default: 50), enabling stepless fine control of broadcasting rhythm.
The VITS model is compatible with SSML markup language, using tags such as phoneme, break and say‑as to precisely control pronunciation, pauses and specific readings.

Real‑time Speech Synthesis
WebSocket streaming synthesis enables simultaneous synthesis and playback with millisecond‑level first‑packet response, supporting real‑time synthesis of both 600‑character short texts and ultra‑long texts.
Large models intelligently predict text emotion and intonation, automatically matching corresponding emotional expressions to support high‑naturalness real‑time dialogue scenarios.

Enterprise‑level System Integration
Offers multiple integration methods including HTTP single synthesis, WebSocket streaming synthesis, standard MRCP protocol and Java/C++ SDKs.
Quickly connects with call center systems such as IVR and outbound calling via MRCP protocol, suitable for voice navigation, automatic outbound calls and content production scenarios.

Application Scenarios
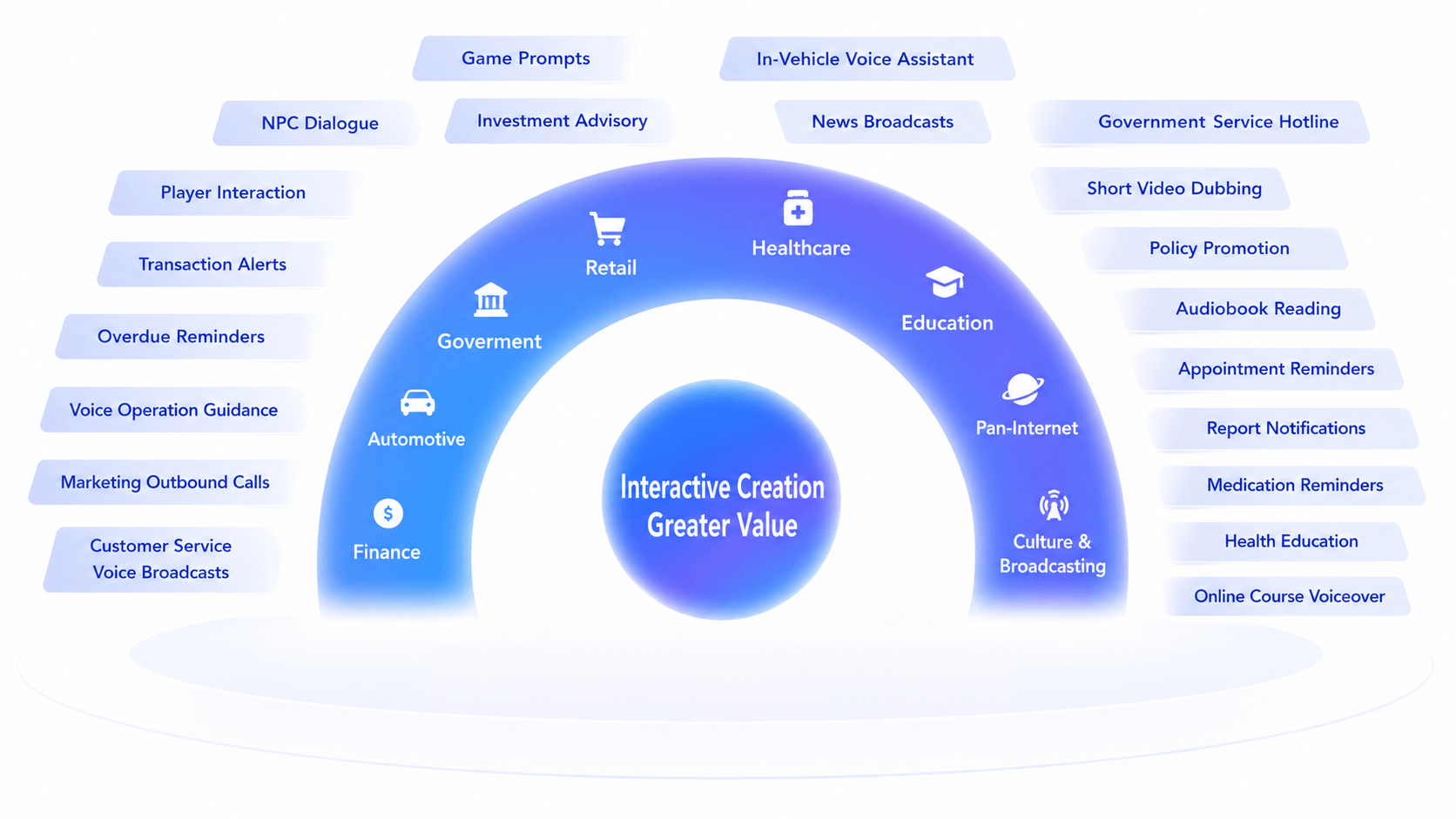

AI‑Driven, Gain Insights One Step Faster
Expert in Conversational Intelligence Solutions. We provide product demos and consultation services.
TTS
Built on deep‑learning and large‑model technologies, it intelligently predicts text emotion, intonation and other features to deliver highly human‑like, smooth and natural speech synthesis services, widely applied in intelligent customer service, audio reading, news broadcasting, smart terminals and other scenarios.

Core Advantages
Product Advantages
- The end‑to‑end VITS model offers 30+ preset voices covering customer service, broadcasting, reading and other scenarios, and supports personalized voice cloning powered by large‑model‑based TTS capabilities.
- Supports SSML markup language for text processing to meet pronunciation requirements under various scenarios.
Technical Advantages
- Supports both efficient end‑to‑end VITS synthesis and large‑model‑driven cloning synthesis.
- Provides dual‑sampling‑rate audio output (8k/16k), fully compatible with playback needs from PSTN telephone channels to high‑definition media.
Service Advantages
- Fully validated by internal Dezhu businesses including intelligent IVR, outbound calls, and practice assistants, it delivers mature and reliable solutions.
- Supports ready‑to‑use public‑cloud APIs and private deployment to meet data‑localization compliance requirements, with multiple authoritative certifications such as CMA and CNAS.
Cost Advantages
- Flexible billing plans including pay‑as‑you‑go and prepaid options.
- Custom voice cloning requires only 5–10 seconds of audio, greatly reducing the costs of traditional voice replication.
Product Capabilities
Voice & Speech Customization
- Built‑in 30+ multi‑style, multi‑gender and multi‑dialect voices to meet mainstream business scenarios such as customer service, broadcasting and reading.
- Large‑model‑powered TTS enables users to independently train personalized cloned voices by submitting audio samples for rapid voice customization.
Fine‑grained Speech Control
- Supports speech‑speed adjustment from level 0 to 100 (default: 50), enabling stepless fine control of broadcasting rhythm.
- The VITS model is compatible with SSML markup language, using tags such as phoneme, break and say‑as to precisely control pronunciation, pauses and specific readings.
Real‑time Speech Synthesis
- WebSocket streaming synthesis enables simultaneous synthesis and playback with millisecond‑level first‑packet response, supporting real‑time synthesis of both 600‑character short texts and ultra‑long texts.
- Large models intelligently predict text emotion and intonation, automatically matching corresponding emotional expressions to support high‑naturalness real‑time dialogue scenarios.
Enterprise‑level System Integration
- Offers multiple integration methods including HTTP single synthesis, WebSocket streaming synthesis, standard MRCP protocol and Java/C++ SDKs.
- Quickly connects with call center systems such as IVR and outbound calling via MRCP protocol, suitable for voice navigation, automatic outbound calls and content production scenarios.
Application Scenarios









 您的账号体验有效期已结束
您的账号体验有效期已结束
外呼电销
View details
智能语音客服系统
View details
自动电话外呼系统
View details
智能质检
View details
电销大模型
View details
得助音视频平台
View details