































ASR
Adopting an advanced self‑developed algorithm that integrates streaming, end‑to‑end, and speech‑language modeling, it converts speech into text quickly and accurately. It supports multiple scenarios including mobile voice interaction, voice content analysis, and robot dialogue. It also delivers high‑precision, low‑latency, and multilingual speech recognition services for clients across finance, automotive, government, and other industries.
Core Advantages

Product Advantages
- Supports multiple dialects and languages to meet global business needs
- Provides stable recognition in complex environments and high availability under noisy conditions.
- Delivers accurate and usable transcription results for direct application deployment
- Compatible with HTTP/MRCP/SDK and other integration methods

Technical Advantages
- Self‑developed ASR is deeply integrated with large language models to boost semantic understanding
- Streaming recognition architecture enables low‑latency real‑time transcription
- Provides a robust speech recognition model with strong anti‑noise performance
- Trained on massive annotated data and optimized for proper nouns

Service Advantages
- Proven successful deployments across dozens of industries with mature multi‑domain cases
- Validated by massive internal business scenarios for stable core‑service operation
- Serves hundreds of millions of daily users with stable performance under high concurrency
- Supports deep customization and optimization for industry‑specific proper‑noun scenarios

Cost Advantages
- Multiple service tiers for on‑demand integration to optimize model inference costs
- Flexible billing options to reduce initial enterprise investment
- Built‑in noise reduction and VAD functions require no extra procurement or development
- Minimizes manual post‑processing and labor costs for later‑stage proofreading
Product Capabilities
Front-end Preprocessing
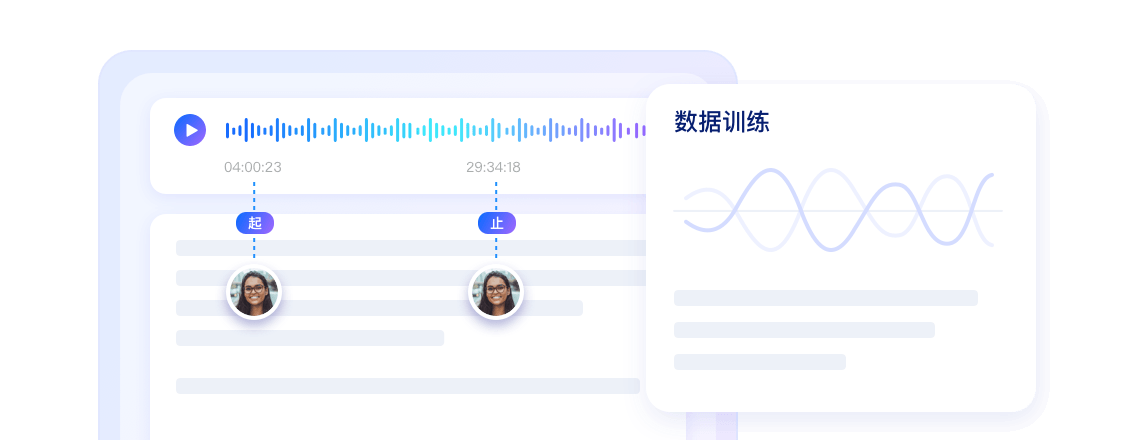
 Voice Activity Detection (VAD) intelligently identifies the start and end of user speech.
Voice Activity Detection (VAD) intelligently identifies the start and end of user speech.
Trained on massive real and simulated noise data, it offers strong noise adaptation capabilities.
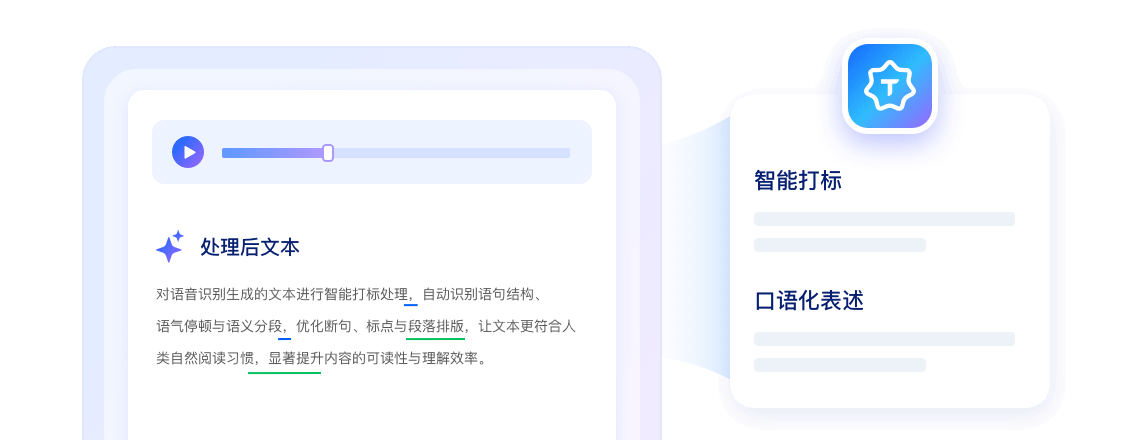
Text Post-processing
Intelligently punctuates recognized text to enhance readability and match human reading habits.
Converts spoken numbers, units, and expressions into standardized formats for text normalization.
Quality Inspection & Auxiliary Analysis
Supports speaker separation and status recognition in single-channel recordings, distinguishing speakers and identifying non-human answers.
Provides real-time voice feature analysis to continuously detect speech rate and volume changes during calls.

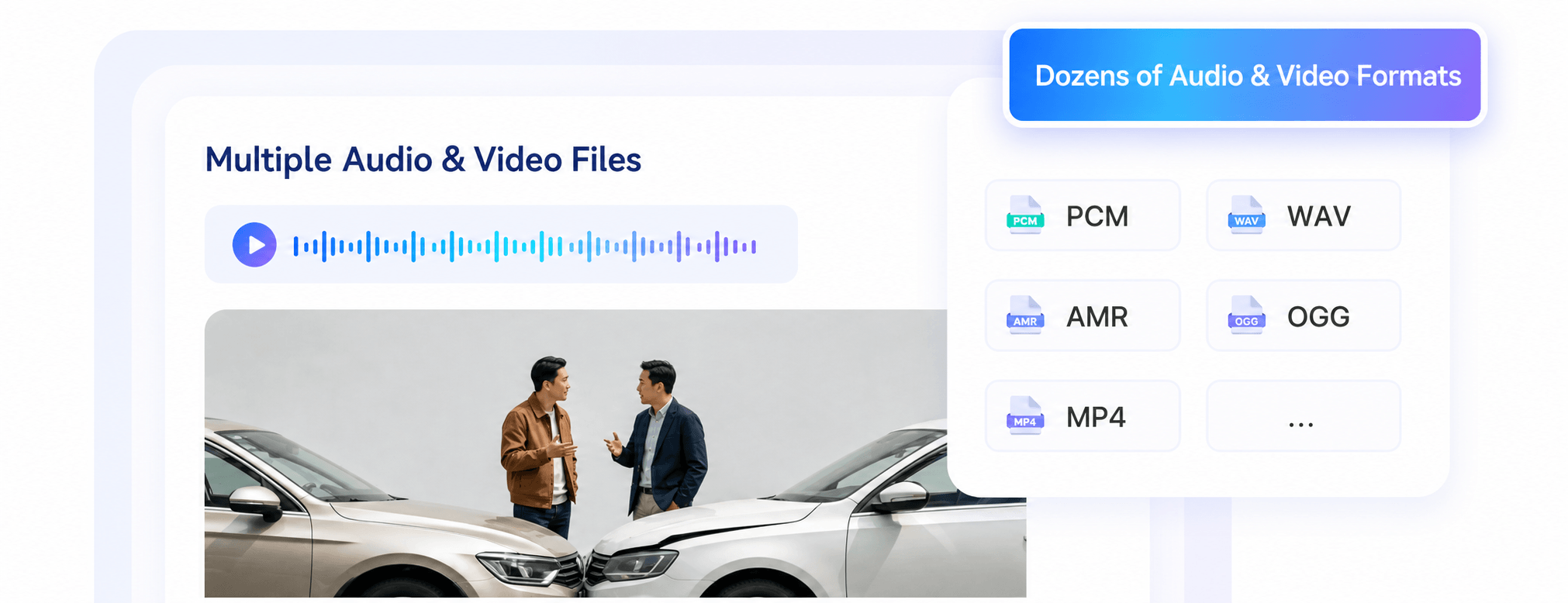
Multi-format Audio & Video Support
Dual-interface access: WebSocket for real-time streaming recognition and HTTP with FFmpeg for easy offline file processing.
Compatible with dozens of audio/video formats including PCM, WAV, AMR, OGG, MP4 for flexible adaptation.
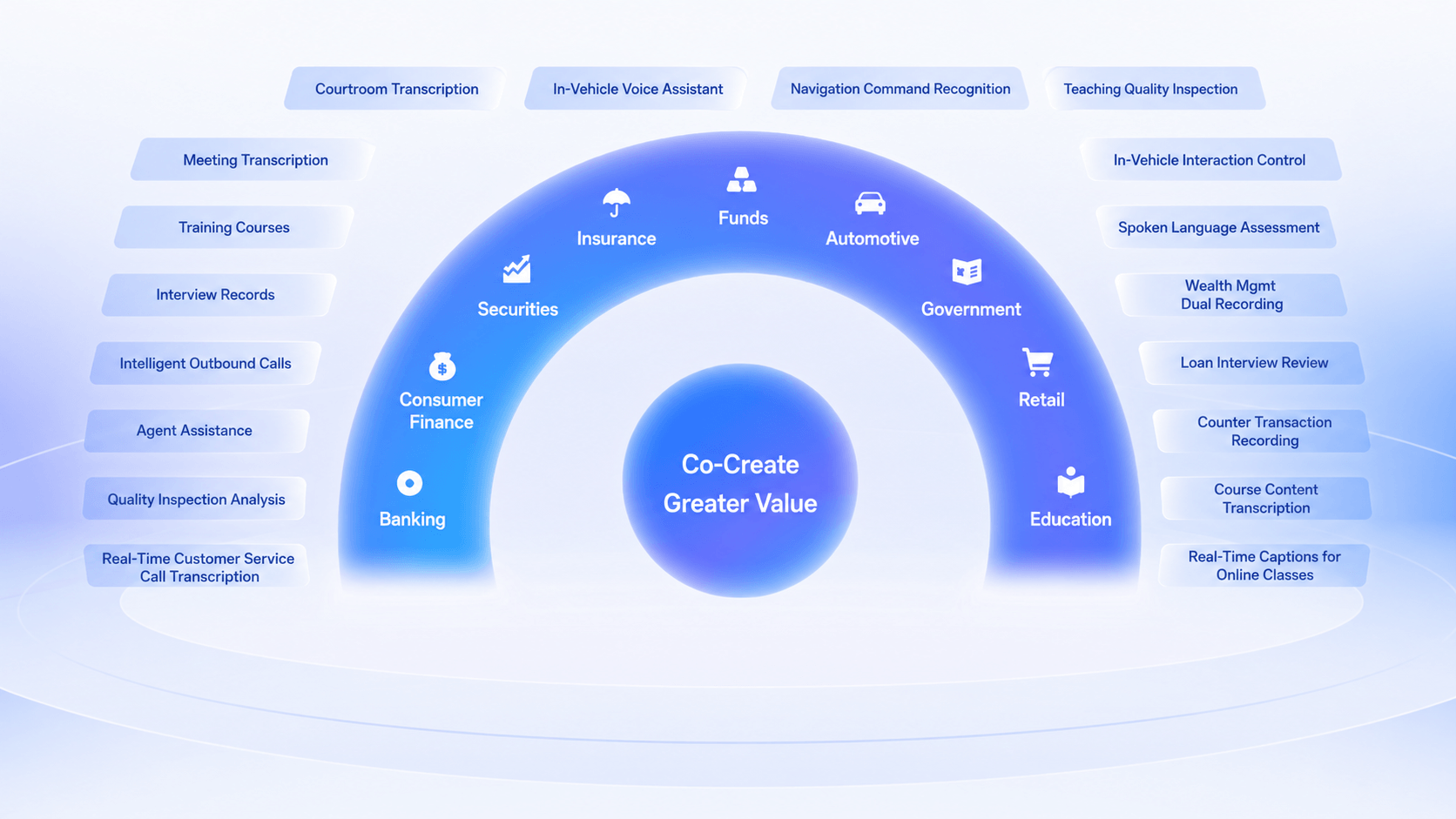
Application Scenarios

AI‑Driven, Gain Insights One Step Faster
Expert in Intelligent Conversation Solutions. We provide product demos and consultation services.
ASR
Adopting an advanced self‑developed algorithm that integrates streaming, end‑to‑end, and speech‑language modeling, it converts speech into text quickly and accurately. Supporting scenarios including mobile voice interaction, voice content analysis and robot dialogue, it provides high‑precision, low‑latency and multilingual‑compatible speech recognition services for finance, automotive, government affairs and other industries.

Core Advantages
Product Advantages
- Supports multiple dialects and languages to meet global business needs
- Stable recognition in complex environments with high availability under noisy conditions
- Delivers accurate and usable transcription results for direct application deployment
- Compatible with HTTP, MRCP, SDK and other integration methods
Technical Advantages
- Self‑developed ASR deeply integrated with large‑language models to enhance semantic understanding
- Streaming recognition architecture enables low‑latency real‑time transcription
- Robust speech recognition model with strong anti‑noise capability
- Trained on massive annotated data and optimized for industry‑specific proper nouns
Service Advantages
- Proven deployments across dozens of industries with mature multi‑domain use cases
- Validated by massive internal business scenarios for stable core‑service operation
- Serves hundreds of millions of daily users with stable performance under high concurrency
- Supports deep customization and optimization for scenarios with proprietary terms
Cost Advantages
- Multiple service tiers for on‑demand integration to optimize model inference costs
- Flexible billing options to reduce initial enterprise investment
- Built‑in noise reduction and VAD functions require no extra procurement or development
- Minimizes manual post‑processing and labor costs for later‑stage proofreading
Product Capabilities
Front-end Preprocessing
- Voice Activity Detection (VAD) intelligently identifies the start and end of user speech.
- Trained on massive real and simulated noise data, it offers strong noise adaptation capabilities.
Text Post-processing
- Intelligently punctuates recognized text to enhance readability and match human reading habits.
- Converts spoken numbers, units, and expressions into standardized formats for text normalization.
Quality Inspection & Auxiliary Analysis
- Supports speaker separation and status recognition in single-channel recordings, distinguishing speakers and identifying non-human answers.
- Provides real-time voice feature analysis to continuously detect speech rate and volume changes during calls.
Multi-format Audio & Video Support
- Dual-interface access: WebSocket for real-time streaming recognition and HTTP with FFmpeg for easy offline file processing.
- Compatible with dozens of audio/video formats including PCM, WAV, AMR, OGG, MP4 for flexible adaptation.
Application Scenarios









 您的账号体验有效期已结束
您的账号体验有效期已结束
全媒体智能客服
View details
MAP(营销自动化平台)
View details
知识助手
View details
IM即时通讯
View details
ai智能机器人
View details
财富助手
View details